

AI data classification is the process of using artificial intelligence to organize and categorize data based on predetermined criteria, enabling efficient data retrieval and analysis. Data classification using AI transforms data management and analytics processes by overcoming the limitations of manual classification, such as the time-consuming nature of the process and the risk of errors. It empowers organizations to make informed decisions based on correct and timely information.
AI data classification can be used for a wide range of applications using a number of different tools. Implementing this process requires a thorough understanding of the steps involved and the classification types, as well as familiarity with various AI-training methods. Here’s what you need to know.
- What Is AI Data Classification?
- 8 Steps of AI Data Classification
- Types of AI Data Classification Algorithms
- 6 Ways to Train AI for Data Classification
- 5 Real-World Use Cases and Tools of AI Data Classification
- Frequently Asked Questions (FAQs)
- Bottom Line: AI Data Classification Improves Accuracy and Efficiency
What Is AI Data Classification?
AI data classification is a process of organizing data into predefined categories using AI tools and techniques. By training AI models to recognize patterns and features within data, new data points can be accurately labeled and tagged based on their similarities to existing examples, facilitating the structured management and analysis of vast volumes of data and unlocking its potential for enhanced decision-making and improved business outcomes.
AI data classification relies on historical data patterns to create order from unstructured information. This capability is essential for predictive analytics, spam filtering, recommendation systems, and image recognition. By refining how AI models process and extract insights from data, it boosts their ability to make credible predictions, detect anomalies, and provide personalized recommendations. This leads to better decision-making, better customer experiences, and increased efficiency across different industries.
8 Steps of AI Data Classification
Implementing a structured approach to AI data classification can significantly enhance the integrity and usability of your data. Following the steps below in sequence will help ensure that each layer of your data is meticulously sorted and primed for data analysis, paving the way for AI to generate precise, actionable insights.
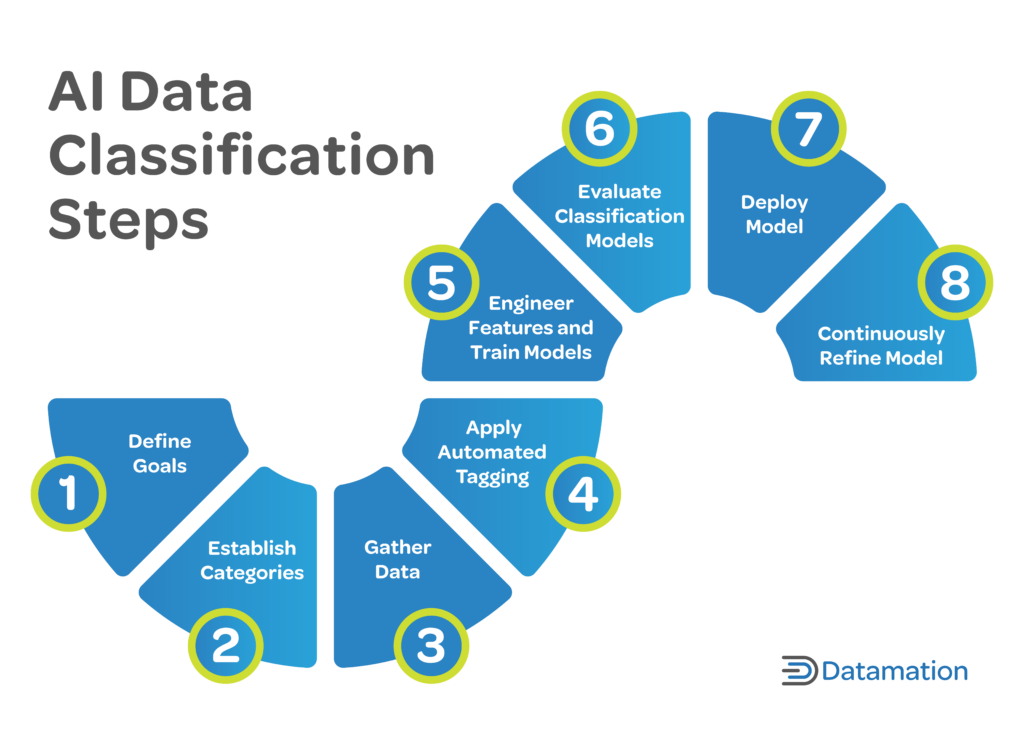
1. Set Clear Goals
Defining clear objectives shapes the entire process. Determine why you need AI data classification—is it to enhance customer experience, predict future trends, or detect anomalies? This understanding lets you tailor the process to meet your specific business requirements and set benchmarks for success.
Setting your goal influences decisions such as data selection, algorithm choice, and evaluation metrics and guides subsequent actions. Developing a data classification policy is part of this initial goal-setting process, as it establishes the framework for how data will be classified and managed throughout the AI model lifecycle.
2. Establish Categories
Effective AI data classification requires the organization of data into distinct categories based on relevance or sensitivity. Defining categories involves establishing the classes or groups that the data will be classified into. The categories should be relevant and meaningful to the problem at hand, and their definition often requires domain knowledge. This step is integral to the AI data classification process as it establishes the framework within which the data will be organized.
3. Gather Data
This step forms the basis for training the AI model and involves collecting a comprehensive and representative dataset that reflects the real-world scenarios the model will encounter. The quality and quantity of the data directly impact the model’s ability to learn and make accurate predictions.
The data must be relevant to the defined categories and objectives, and diverse enough to capture various aspects of each category. Data gathering also entails data cleaning and preprocessing to handle missing values, outliers, or inconsistencies. The success of the AI data classification process heavily relies on the quality of the gathered data.
4. Apply Automated Tagging
This key step leverages AI algorithms to automatically sort data into the predefined categories, which is particularly useful when dealing with large volumes of data. Automated tagging can quickly and precisely classify data, reducing the need for manual effort and increasing scalability. This not only simplifies the classification process but also promotes consistency in data tagging, boosting efficiency.
5. Engineer Features and Train Models
Feature engineering sets the stage for effective learning, while model training is where the actual learning happens. In feature engineering, data is analyzed to identify or create new features that are most relevant for classification. In model training, the classification model is exposed to the data, and it learns to recognize patterns and relationships between the features and the categories. Both steps are interdependent and imperative to creating a precise AI data classification model.
Choosing an AI data classification tool is part of the process of training models, and different tools may offer varied algorithms, functionalities, and performance characteristics that can affect the effectiveness of the classification models. Selecting the right tool during this step is necessary to reach your data classification goals.
6. Evaluate AI Classification Models
In this step, trained models are tested on a separate dataset to assess their performance. Key metrics such as precision and recall are typically used to quantify the model’s success in classifying data. Evaluating AI data classification models helps you discover their strengths, weaknesses, and any potential areas for improvement that call for additional training or feature engineering. This step ensures that the classification process meets the desired quality standards and aligns with the defined objectives.
7. Deploy Models
The trained and evaluated models are put into practical use in this stage. Model deployment entails integrating the models into operational environments or business workflows, allowing for the real-world application of the classification outcomes. During this stage, the classification models start categorizing new, real-time data, enabling successful data classification at scale.
8. Continuously Refine and Adjust
Even after the models are deployed and in production, they need to be constantly monitored and adjusted to accommodate changes in business requirements, technology capabilities, and real-world data. This step could include retraining the models with fresh data, modifying the features or parameters, or even developing new models to meet new demands. This step helps maintain the accuracy and relevance of the models in the face of evolving data trends and business needs.
Types of AI Data Classification Algorithms
AI data classification algorithms can be split into two primary categories based on their learning behavior: eager learners and lazy learners. These categories reflect differing approaches to how AI models process and utilize training data, which are fundamental in the classification process.
Eager Learners
Also known as model-based learners, eager learners build a specific model during the training process using the training data that represents the learned knowledge and can be directly used for making predictions on new instances. Eager learners typically require more computational resources during the training phase compared to lazy learners. Examples of eager learners include the following:
- Decision Trees: Intuitive and straightforward algorithms that create a flowchart-like structure to classify data based on features and decision rules, decision trees start with a root node representing the entire dataset. The root node is split into child nodes that each represent subsets of the data. Decision trees are widely used in customer segmentation, fraud detection, and disease diagnosis.
- Logistic Regression: This highly adaptable algorithm is widely used in binary classification scenarios, where it assesses the probability of a binary outcome based on multiple predictor variables. Common applications include predicting customer attrition, identifying spam messages, and detecting fraudulent transactions in banking and financial domains.
- Random Forests: A type of ensemble learning algorithm used in credit scoring, medical diagnosis, and fraud detection. Known for their robustness, random forests construct multiple decision trees and combine their predictions to make a final classification, providing greater interpretability,
- Support Vector Machines (SVM): Used in complex scenarios such as image and text categorization and bioinformatics, SVM identifies the optimal hyperplane (a decision boundary) that segregates data points into distinct classes while maintaining the widest possible margin between them. This approach is advantageous when dealing with high-dimensional data and non-linearly separable classes, as it can capture intricate relationships within the data.
- Neural Networks: These algorithms take inspiration from the human brain’s structure and functionality. These are advanced computational models that comprise layers of interconnected nodes, often referred to as “neurons,” that process and transform input data into predictive outputs. Neural networks can be used to classify input data into different categories or classes based on learned patterns from training data.
- Naïve Bayes Classifiers: A machine learning (ML) algorithm usually used in classification tasks, this generative learning algorithm follows the principles of probability to categorize data. These classifiers are advantageous when there is limited knowledge about the distribution of data.
Lazy Learners
Also known as instance-based learners, lazy learner algorithms store all the training instances in memory instead of learning a model. This stored data serves as the basis for making predictions. When it’s time to classify a new instance, the lazy learner efficiently compares it to the existing instances in its memory.
Based on this comparison, the learner assigns a label to the new instance. Lazy learners specialize in handling complex and nonlinear data, making them suitable for real-world applications. In addition they’re relatively easy to implement compared to other learning algorithms. However, lazy learners can be expensive, especially for large datasets.
The K-Nearest Neighbors (KNN) algorithm is an example of a lazy learner. KNN is a simple yet powerful machine learning algorithm used for classification and regression tasks. The key idea behind it is to assign a label or predict a value for a new data point based on the labels or values of its closest neighbors in the training dataset. KNN is often used in scenarios where there is little prior knowledge about the data distribution, such as recommendation systems, anomaly detection, and pattern recognition.
6 Ways to Train AI for Data Classification
There are six common ways you can train AI for data classification. These methods vary in their approach and complexity and are chosen based on the objectives, the availability of data, and the specific requirements of your business.
Supervised Learning
This is a well-established method in data classification, which involves training a model using a dataset where each data point is associated with a specific label. Commonly used algorithms for this learning type include logistic regression, decision trees, SVMs, Naïve Bayes, KNN, and neural networks.
Supervised learning is applied in email spam detection, sentiment analysis, image classification, medical diagnosis, and credit scoring. For instance, in email spam detection, a supervised learning model can be trained to classify emails into spam or non-spam categories based on the sender’s email address, subject line, and content. Similarly, in medical diagnosis, it can be trained to predict the presence or absence of a disease based on patient symptoms, medical history, and test results.
Unsupervised Learning
Unlike supervised learning, algorithms analyze and interpret data for classification without prior labeling or human intervention in unsupervised learning. This approach allows algorithms to discover underlying patterns, data structures, and categories within the data.
Clustering, anomaly detection, and association rule mining are examples of unsupervised learning algorithms that extract meaningful insights and relationships from data. These algorithms are employed to segment markets, provide personalized product recommendations, detect outliers in data, and identify communities in social networks.
Semi-Supervised Learning
Semi-supervised learning uses both labeled and unlabeled data in model training, which is especially beneficial when it’s difficult or costly to obtain sufficient labeled data. For example, semi-supervised learning can enhance model performance in speech analysis using unlabeled data, such as audio files without transcriptions, to better understand the variations and nuances in speech. This can lead to more accurate classification when the model encounters new, similar audio files.
Reinforcement Learning
Reinforcement learning trains AI for data classification by guiding it to learn through trial and error. In this approach, the AI agent interacts with its environment, making decisions and receiving feedback in the form of rewards or penalties.
By exploring different actions and observing the outcomes, the AI learns which actions lead to better classification results. Over time, through continuous learning and optimization, the AI improves its classification precision by maximizing the total reward accumulated during the training process. Reinforcement learning is applied in robotics, self-driving cars, and gaming bots for chess and poker games.
Active Learning
This data labeling and selection technique is gaining prominence in AI tasks like text classification, image annotation, and document classification. This iterative approach involves selecting the most informative data points for labeling, learning from the labeled data, and refining predictions. The process continues until the desired level of model performance is attained or all data is labeled. This method is especially beneficial when data labeling is expensive or time-consuming, prompting efficient use of labeled data.
Transfer Learning
This method involves transferring knowledge from pretrained models to new tasks. It reduces the need for labeled data and often elevates classification performance, making it suitable in domains with limited or difficult-to-obtain labeled data. Transfer learning is commonly applied in image recognition and NLP for text classification or sentiment analysis.
5 Real-World Use Cases and Tools of AI Data Classification
AI data classification plays a key role in refining processes across different fields and industries by organizing and categorizing data effectively. Organized data boosts decision-making speed and accuracy, ensures compliance, and reduces redundancy.
Customer Segmentation
AI data classification is used in customer segmentation to divide customers into groups with shared characteristics or behaviors. ML models analyze demographics, purchasing history, and interactions to classify customers into segments with similar needs or preferences.
This segmentation allows businesses to tailor marketing strategies and offerings to better meet diverse customer needs. An e-commerce company might classify customers as “frequent shoppers,” “budget-conscious buyers,” or “luxury seekers” based on behavior and preferences. Examples of AI data classification tools for this application include Peak.ai and Optimove.
Product Recommendation
In e-commerce product recommendation systems, AI categorizes products based on user behavior, preferences, and purchase history. It makes use of collaborative filtering or content-based filtering techniques to match users with relevant products.
For example, a user who frequently buys electronics might be classified as a “tech enthusiast” and receive recommendations for headphones or smartphones. Examples of tools for product recommendation are involve.me and Personyze.
Fraud Detection
AI data classification tools aid in fraud detection by analyzing patterns in transactional data and categorizing activities as either legitimate or suspicious. ML models learn from historical data, detecting anomalies or deviations from normal behavior that may indicate fraud.
For example, if a credit card transaction significantly deviates from a user’s typical spending patterns or occurs in a location known for fraudulent activities, the AI model can flag it for further investigation. Amazon Fraud Detector and Simility from PayPal are examples of AI classification tools used in this use case.
Network Traffic Analysis
In network security, AI data classification tools analyze network traffic and detect potential threats or anomalies. By classifying network packets based on their characteristics, AI can detect suspicious patterns indicative of malicious activity, such as network intrusions or denial-of-service attacks.
By differentiating between normal and abnormal network behavior, it enables security teams to respond promptly to security incidents. For instance, AI algorithms can classify incoming network traffic as either legitimate user requests or suspicious traffic generated by a botnet. Fujitsu Network Communications and Datadog Network Monitoring use AI data classification for network analysis.
Medical Diagnosis
AI data classification tools aid healthcare professionals in interpreting medical images, such as X-rays, MRI scans, and pathology slides. ML algorithms are trained on labeled datasets containing images with corresponding diagnoses.
Once trained, these models can classify new images by identifying patterns or abnormalities indicative of specific diseases or conditions. Examples of medical diagnosis solutions that use AI for data classification include MedLabReport and CardioTrack AI.
Frequently Asked Questions (FAQs)
Why is Data Classification Important?
Data classification is important for organizing, managing, and protecting sensitive enterprise data, ensuring compliance with regulations, and streamlining data management. It facilitates the separation of old and unnecessary data and promotes better operational effectiveness by establishing data sensitivity levels and implementing suitable cybersecurity measures based on business standards.
What are the Risks of No Data Classification?
Without data classification, organizations may not adequately protect sensitive data, leading to increased risk of data breaches and compromised information. Failure to adequately protect confidential information can also result in significant financial penalties, cyber incidents, costly lawsuits, reputational damage, and potential loss of the right to process certain types of information. Data classification brings benefits such as heightened confidential data protection, optimized resource allocation, facilitated internal alignment, and easier enterprise data mapping within your organization.
Bottom Line: AI Data Classification Improves Accuracy and Efficiency
AI data classification is transforming data management by sorting and analyzing data quickly and accurately, helping businesses stay ahead. It empowers organizations to identify their data types, locations, and handle sensitive information securely. This process also ensures compliance with regulations. Moving forward, AI’s role in data analysis will grow, deep learning will become more common, and AI will incorporate technologies like cloud computing and big data analytics, elevating data classification further.
A data classification policy is vital in AI data classification as it outlines the criteria to categorize and manage various types of data within your organization. It plays a vital role in ensuring appropriate protection measures are in place, which becomes especially critical when training AI models with sensitive data. Get a free data classification policy template and learn how to create your own by reading our data classification policy article.