

Data classification is a component of the data management process in which data is categorized based on various characteristics to reinforce data security, aid regulatory compliance, and enable efficient data management. Data classification helps companies comply with regulations, cut costs, manage risks, and maintain data integrity.
This process typically includes identifying and categorizing data types and implementing security measures accordingly. Generally, data management teams and executives or IT professionals must work together to classify data and ensure its alignment with business policies.
Despite its technical nature, understanding how to perform data classification is a must for organizations, as it is a key element of a comprehensive data governance strategy.
- What Is Data Classification?
- How Does Data Classification Work?
- Data Classification Types
- Data Classification Techniques
- Advantages of Data Classification
- Disadvantages of Data Classification
- Data Classification Use Cases and Examples
- Frequently Asked Questions (FAQs)
- Bottom Line: Data Classification Is Important
What Is Data Classification?
Data classification entails organizing data into categories based on content, sensitivity, and importance to promote efficient data use and protection, simplifying locating and retrieving information. It also involves tagging data to make it easier to search and track, reducing duplications and cutting storage and backup costs.
Data classification is also a foundational process for risk mitigation that encompasses both structured and unstructured data analyses. It gives valuable insights into user-generated sensitive information and helps organizations answer essential questions about their data, thereby shaping their risk mitigation strategies and governance policies.
How Does Data Classification Work?
Your organization can establish a robust data classification system that improves data management, supports compliance efforts, and strengthens data security by working through a series of seven steps to identify, categorize, label, control access to, encrypt, manage, and audit data throughout its entire lifecycle.
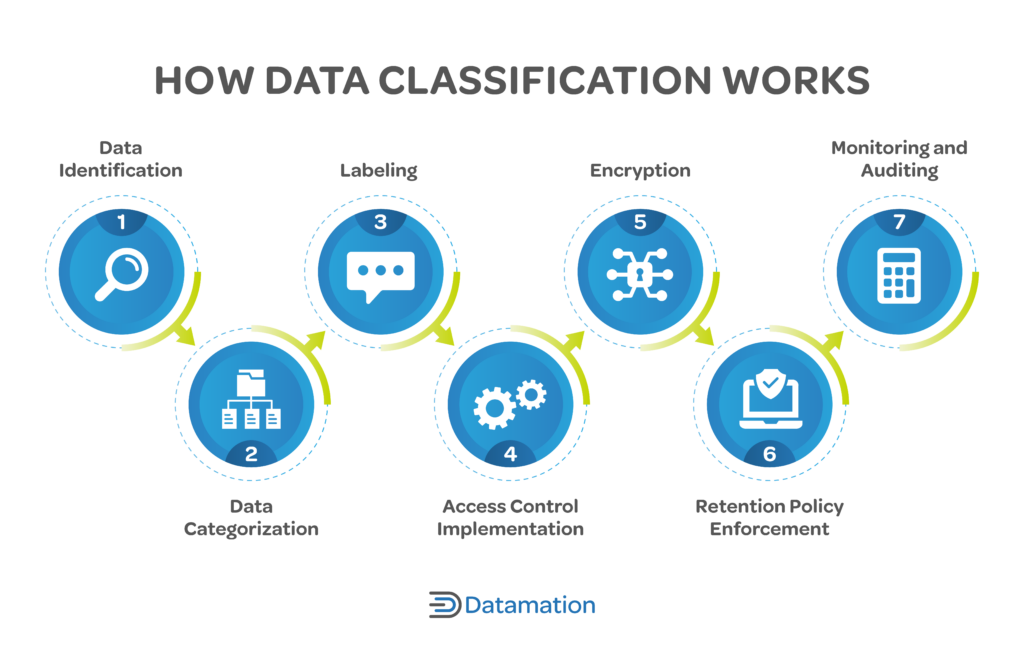
Data Identification
Data identification includes recognizing and distinguishing the different types of enterprise data for classification. The goal is to gain insights into such specifics as source, format, and purpose for accurate data classification based on the relevance of the data to your business operations and objectives.
As part of a solid data management strategy, an extensive data classification policy is necessary during the identification process.
Data Categorization
This stage builds on the insights from data identification, grouping data based on predefined criteria. It requires a systematic classification process according to factors such as content, sensitivity, and significance. The idea is to create a structured framework for efficient data management and control.
Labeling
Labeling is an important aspect of data classification, where identified and categorized data is assigned specific tags or labels. These labels serve as markers to signify the data’s nature, criticality, or purpose. Through this process, each piece of information receives a clear identifier, indicating its classification level and guiding subsequent handling procedures.
Access Control
After data is labeled and categorized, you roll out measures to limit who gets access to it. These access controls help make sure that only the right people or systems can connect with specific data sets, keeping information secure.
Data Encryption
Encryption adds an extra layer of security to access controls, especially for confidential and restricted information. It ensures that even if someone gains access, the data remains unreadable without the right decryption keys. Encryption can protect sensitive data during storage, transmission, and processing, safeguarding digital assets in accordance with stringent security protocols.
Retention Policies and Enforcement
The next step is implementing a methodical approach to managing data throughout its lifecycle. You must establish guidelines on how long varied types of information should be retained to comply with regulatory requirements. By enforcing retention policies, your business can fine-tune data management, mitigate risks associated with unnecessary data storage, and maintain a compliant data environment.
Monitoring and Auditing
After enforcing your retention policies, you must actively track and evaluate how individuals or systems access and use your data. Keep tabs on who interacts with your information and how to safeguard against unauthorized access and find ways you can continuously upgrade your data management practices.
In this step, following data classification trends becomes particularly important—as new types of data emerge and regulations evolve, your monitoring and auditing strategies should adapt accordingly. For instance, the rise of artificial intelligence in data classification can be leveraged to increase the accuracy of your audits. Similarly, changes in data protection laws should be reflected in your compliance checks.
Data Classification Types
Data classification types serve as distinct labels for various categories of information, guiding how each should be handled, accessed, and protected within the organizational ecosystem. THe following are the seven key types of data classification:
- Public Data: Information intended for public sharing that does not endanger the organization if it is disclosed—government publications, for example.
- Internal Data: Data intended for internal use within the company, typically not intended for public disclosure but not highly sensitive—employee information, for example.
- Confidential Data: Sensitive information requiring a higher level of protection—disclosure may have adverse effects on the organization—internal investigations, for example.
- Restricted Data: Strictly-regulated data, limited to specific individuals or departments due to its sensitivity—trade agreements and contracts, for example.
- Private Data: Personal information about individuals, subject to privacy regulations and needing careful handling to prevent unauthorized access—contact information, for example.
- Critical Data: Sensitive information vital to the organization’s operations. Its exposure could result in serious repercussions—company infrastructure and system configurations, for example.
- Regulatory Data: Information that must adhere to specific regulations and compliance standards, necessitating careful management and protection—patient health records, for example.
Data Classification Techniques
Many organizations use multiple techniques for data classification. Choosing a technique is not a one-size-fits-all approach but a strategic decision influenced by the unique details of the data you’re working with. Some organizations even combine different techniques to create a comprehensive data classification strategy to suit their complex needs.
Rule-Based Classification
Rule-based classification, as the name suggests, calls for creating a set of rules to categorize data into distinct groups or classes. These rules are derived from analyzing data characteristics and attributes, and serve as decision criteria for assigning data to particular categories.
This technique is commonly used in industries where clear and interpretable decision-making is imperative, like credit scoring in financial institutions and patient risk stratification in healthcare organizations.
Data Labeling
This technique is fundamental practice in data classification, and many organizations use metadata or descriptive tags to indicate data characteristics or categories. Data labeling aids in maintaining organized datasets and is commonly used in conjunction with other classification techniques.
Data labeling is valuable in training machine learning models, offering labeled examples for algorithms to learn and generalize patterns. In addition, this data classification technique is used in the healthcare industry for annotating medical images and detecting specific features or anomalies.
Machine Learning Classification
Machine learning (ML)-based classification uses algorithms and statistical models to allow systems to learn and make predictions or without being explicitly programmed. This technique is quickly gaining popularity, especially in larger organizations dealing with vast and complex datasets that may be challenging to define manually.
ML algorithms analyze patterns and characteristics within large datasets to automatically categorize and label data into predefined classes or categories, saving time and effort while increasing precision over time.
Global industries, including international e-commerce and marketing corporations, apply this classification technique in big data environments. It allows them to automatically segment customers based on their behavior, preferences, and interactions with products or services.
Content-Based Classification
This technique organizes data according to its inherent features and characteristics, as well as historical interactions. It is used to make personalized recommendations, improving user experience and engagement across platforms by delivering content suggestions tailored to individual preferences and needs.
Streaming services use content-based classification to recommend movies or songs to users based on the genre, actors, or musicians they have previously enjoyed.
User-Based Classification
User-based classification, also called collaborative filtering, is a data classification technique that recommends items or content to users based on the selections and behaviors of other users with similar tastes. It enhances personalization by leveraging the collective preferences of a community of users.
This technique is common in recommendation systems within social media platforms, e-commerce industries, and streaming services.
Advantages of Data Classification
Data classification brings numerous advantages that contribute to a resilient and well-managed data environment, addressing both security concerns and regulatory requirements while optimizing operational processes:
- Heightened Security and Data Protection: Classifying data by sensitivity and importance lets you customize security measures, including access controls, encryption, and retention policies. This ensures the highest level of protection for sensitive information.
- Risk Mitigation and Regulatory Compliance: Systematically categorizing data lets you determine potential risks associated with different types of information, helping ensure your business adheres to data privacy regulations and avoids penalties, legal consequences, and reputational damage.
- Efficient Resource Allocation: Data classification gives you confidence that sensitive data receives the necessary resources for safe storage and retrieval, optimizing overall system performance. The process also reduces redundancy, streamlining backup processes and minimizing unnecessary resource usage.
- Tailored Access Controls and Privacy Compliance: Individuals or systems only get access to the data relevant to their roles, ensuring a need-to-know basis with tailored access controls from data classification. You can apply specific privacy measures to particular data categories, aligning your business practices with privacy standards.
- Improved Incident Response and Data Lifecycle Management: Data classification presents a roadmap for handling data, helping you find the most sensitive data and prioritize a response in the event of a data breach. Also, understanding data category sensitivity helps in applying controls, retention policies, and disposal methods.
Disadvantages of Data Classification
While data classification brings numerous benefits, it’s important to note that its implementation isn’t without potential challenges:
- Complex Implementation: Deploying a comprehensive data classification system involves defining criteria, rules, and ensuring consistency across diverse datasets. It requires thorough planning, understanding of business requirements, and potential integration with existing systems.
- Costs: Initial setup and integration costs associated with data classification can be substantial, including investments in data classification software and training programs—maintaining a data classification system may also require additional resources in terms of technology, personnel, and ongoing monitoring efforts.
- Ongoing Maintenance: Regular updates and maintenance are needed to make sure that process remains effective and aligned with changing business needs, industry regulations, and emerging data types.
- Misclassification Risks: Mistakenly categorized information, either intentionally or unintentionally, can result in inadequate protection for important data or unnecessary security measures for non-sensitive data. This could lead to data breaches, compromised security, and issues in trying to meet regulatory compliance.
Data Classification Use Cases and Examples
Data classification is a widely adopted practice in several industries, offering a systematized approach to organizing and securing information based on its attributes. It is instrumental in addressing industry-specific challenges and optimizing information security.

Financial Institutions
Banks and financial institutions use data classification to manage, categorize, and protect vast volumes of data, including transactions, customer details, and market trends. The process helps detect and prevent fraudulent activities, maintaining strict adherence to regulatory frameworks—particularly anti-money laundering (AML) regulations—and safeguarding sensitive customer information.
The classified data serves as a structured input for data mining processes, too. By applying data mining techniques to the classified data, these organizations can uncover hidden patterns, predict future trends, and make informed decisions, elevating their services and operations. An example of this is the HSBC Nudge app, which evaluates the customer’s account, determines trends in their spending habits, and sends regular, targeted digital “nudges” to make people aware of their spending.
Healthcare Organizations
Hospitals, clinics, and healthcare organizations classify patient records, medical history, and other health-related information as protected health information (PHI). As a result, they can protect sensitive patient data in compliance with the Health Insurance Portability and Accountability Act (HIPAA) regulations. Healthcare institutions that deal with PHI, such as Cleveland Clinic and UnitedHealth Group, rely on data classification to identify, label, and secure PHI.
E-Commerce Platforms
E-commerce platforms classify customer data based on purchase history, preferences, and demographics to create targeted marketing campaigns, recommend personalized products, and give customers a positive experience—ultimately driving sales and customer loyalty.
Amazon and eBay use data classification to organize and understand customer preferences and shopping behaviors. This equips them to offer personalized product suggestions and take customer service experiences to the next level.
Technology Companies
Technology companies classify their intellectual property, such as software code, patents, and trade secrets. This helps them apply strict access controls, safeguard valuable assets, and prevent unauthorized use or disclosure of their newest innovations.
Intel employs a data classification system to categorize its products for export control. This system plays a major role in safeguarding the intellectual property associated with its products.
Frequently Asked Questions (FAQs)
Why Is Data Classification Important?
Data classification is important because it enables your organization to strategically identify and secure the most critical data. It promotes operational efficiency by supporting robust data analytics, security systems, and streamlined data lifecycle management. It also facilitates adherence to data handling guidelines and regulatory mandates like HIPAA, which is required for businesses in regulated sectors.
Is Data Classification Required?
The requirement for data classification varies depending on your organization, data type, regulations, and risk tolerance. The entire process is a proactive approach to safeguarding information and maintaining efficiency.
In some industries, regulatory bodies mandate data protection and privacy measures, such as General Data Protection Regulation (GDPR) or HIPAA. These regulations obligate organizations handling sensitive data, such as financial information, intellectual property, or personal identifiable details, to classify and protect sensitive information.
But even without regulations, many organizations adopt data classification as a best practice to manage data and reduce data breach impacts.
Bottom Line: Data Classification Is Important
Data classification is of utmost importance as it can help your organization allocate resources strategically and ensure high-value data security. It bolsters data management, decision-making, regulatory compliance, and sensitive information protection.
Data classification has several types, and each type demands a tailored approach. Not all data is created equal, and recognizing the differences is key. By acknowledging distinctions, you can implement appropriate security measures, access controls, and retention policies for every category.
Choose the right data classification technique according to the nature and goals of your business and leverage data classification matrices and tools to accurately categorize your enterprise data.
Data is a valuable business asset, and how you classify and manage it can significantly impact your business’s success. So, invest time and resources in data classification – it’s a decision that will pay dividends in the long run.
Read our buyer’s guide on the top-rated data classification software tools to find out which products we rated most highly and how they compare against enterprise data classification requirements criteria.