

Machine learning vs. deep learning isn’t exactly a boxing knockout – deep learning is a subset of machine learning, and both are subsets of artificial intelligence (AI). However, there is a lot of confusion in the marketplace around the definitions and use cases of machine learning and deep learning, so let’s clear up the confusion.
· Artificial intelligence (AI) is the study of simulating and imitating intelligent human behavior in computer systems and machines.
· Machine learning is a sub-domain of AI, and uses algorithms to apply AI concepts to computing systems. Computers identify and act upon data patterns, and over time learn to improve their accuracy without explicit programming. Machine learning is behind analytics like predictive coding, clustering, and visual heat maps.
· Deep learning is a sub-domain of machine learning and is another name for artificial neural networks. Deep learning computer networks simulate the way a human brain perceives, organizes, and makes decisions from data input. Skynet aside, deep learning exists today.
Machine Learning vs. Deep Learning
Although deep learning is a subset of machine learning, there is some confusion in the marketplace about the difference between the two. At this point, you are much more likely to employ machine learning in your applications than deep learning, which is still a developing technology and expensive to deploy. But some offerings are already in the market, and over time deep learning will become more common.
Let’s look at the distinctions and usage cases between the two.
Machine Learning
As a subset of AI, machine learning uses algorithms to parse data, learn from the results, and apply the learning to make decisions or predictions. Examples include clustering, Bayesian networks, and visual data mapping. In eDiscovery and compliance investigations for example, heat maps and visual clusters can present graphic search results to humans, who can use the results to drill down into otherwise obscure data.
Machine learning technology falls into two types: supervised machine learning and unsupervised machine learning. Supervised learning depends on a human-generated seed set that teaches the software how it should define data. Predictive coding is a prime example. The software refers to the seed set to match data patterns to a relevancy percentage. Over time the predictive coding tool learns from ongoing reviewer feedback.
Unsupervised machine learning depends on recognizing patterns contained within data and comparing them to other data or search queries. Machine learning algorithyms learn over time as data sets grow and more patterns emerge. Unsupervised machine learning includes clustering, concept search, and near-dedupe.
For example, clustering matches similar text and metadata between documents and presents the data in visual clusters. Concept search expands text-based queries by identifying and matching concepts. Near-dedupe compares similar data and excludes documents based on degrees of similarity, while email threading links orphaned emails to their appropriate threads. Each of these analytics learns from its actions to increase performance and accuracy over time.
Machine learning infrastructure varies widely. Single systems can enable limited clustering or network traffic reporting, while large systems comprise dozens of servers and Massively Parallel Processing (MPP) architecture for massive data across multiple data sources.
Deep Learning
Deep learning, also called artificial neural networks, is based on algorithms like all machine learning. However, it does not use task-specific algorithms like data classification. Instead it mimics human brain structure and function by recognizing representative data from unstructured input and outputting accurate actions and decisions.
Learning can be supervised or unsupervised, meaning that large neural networks can accept tagged input but do not require it. Learning programs teach a neural network how to construct different processing layers, but when a network is processing input they create their own layers according to data input and output. This level of deep learning allows the neural networks to automatically extract features from raw data without additional human input.
The neural network consists of multiple simple connected processors called neurons, which are mathematical functions created to mimic the neurons in the human brain. These artificial neurons make up the units of the neural network
Simply stated, each neuron receives two or more inputs, processes them, and outputs a result. Some neurons receive their input from external sensors, while other neurons are activated by input from other active neurons. Neurons may either activate additional neurons, or may influence the external environment by triggering actions. All activity occurs with self-created hidden layers, where each successive layer inputs the output of the previous layer.
In practical terms, neural networks ingest unstructured data: sound, text, video, and images. The networks separate the data into data chunks and sends them to individual neurons and layers for processing. Once this discrete processing is complete, the network produces the final layer of output.
Massive scalability is the key to neural networks. The performance of a neural network depends on how much data it can ingest, train on, and process; more data means better results. This is another distinction from more basic machine learning, whose algorithms commonly plateau at a certain level. Deep learning scales its performance bound only by its computing resources. Thus the “deep” part of neural networks: the more computational resources, the deeper the levels, the more extensive the output. Although deep learning is hardly quick and easy, more compute processing power at lower prices revolutionized research and development.
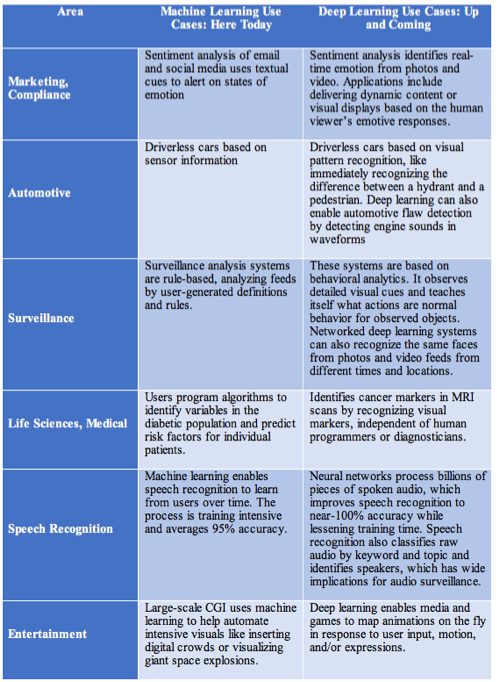
Popular Use Cases for Machine Learning and Deep Learning
It’s important to remember that the use cases for machine learning are already in the market. The uses cases for deep learning are primarily development targets at this stage with limited commercialization. Some of the use cases are similar: the distinction is that the neural networks can grow to near-infinite scales of learning and output. Machine learning is more constrained and suitable to specific, practical computing tasks. Also keep in mind that two are not mutually exclusive.
Looking to the Future
You won’t find deep learning/artificial neural networks on every street corner. They universally require large amounts of tagged data for supervised learning, or massive amounts of unstructured data for unsupervised learning. Deep learning technology developers either need to spend significant time labeling and inputting data to the neural network, or they need to input millions of unstructured objects to achieve unsupervised learning.
In today’s data-intensive world, having sufficient data is not the problem. Tagging sufficient data, or introducing sufficient unlabeled data to a neural network is a challenge. And although processing power has grown and prices have dropped, intensive computations still require a good deal of investment into systems and support.
Nevertheless, deep learning has promising use cases across many different business verticals. Deep pocket companies like Google and Facebook are investing in deep learning to develop these practical applications, and other developers are following suit.
RELATED NEWS AND ANALYSIS
-
Huawei’s AI Update: Things Are Moving Faster Than We Think
FEATURE | By Rob Enderle,
December 04, 2020 -
Keeping Machine Learning Algorithms Honest in the ‘Ethics-First’ Era
ARTIFICIAL INTELLIGENCE | By Guest Author,
November 18, 2020 -
Key Trends in Chatbots and RPA
FEATURE | By Guest Author,
November 10, 2020 -
FEATURE | By Samuel Greengard,
November 05, 2020 -
ARTIFICIAL INTELLIGENCE | By Guest Author,
November 02, 2020 -
How Intel’s Work With Autonomous Cars Could Redefine General Purpose AI
ARTIFICIAL INTELLIGENCE | By Rob Enderle,
October 29, 2020 -
Dell Technologies World: Weaving Together Human And Machine Interaction For AI And Robotics
ARTIFICIAL INTELLIGENCE | By Rob Enderle,
October 23, 2020 -
The Super Moderator, or How IBM Project Debater Could Save Social Media
FEATURE | By Rob Enderle,
October 16, 2020 -
FEATURE | By Cynthia Harvey,
October 07, 2020 -
ARTIFICIAL INTELLIGENCE | By Guest Author,
October 05, 2020 -
CIOs Discuss the Promise of AI and Data Science
FEATURE | By Guest Author,
September 25, 2020 -
Microsoft Is Building An AI Product That Could Predict The Future
FEATURE | By Rob Enderle,
September 25, 2020 -
Top 10 Machine Learning Companies 2020
FEATURE | By Cynthia Harvey,
September 22, 2020 -
NVIDIA and ARM: Massively Changing The AI Landscape
ARTIFICIAL INTELLIGENCE | By Rob Enderle,
September 18, 2020 -
Continuous Intelligence: Expert Discussion [Video and Podcast]
ARTIFICIAL INTELLIGENCE | By James Maguire,
September 14, 2020 -
Artificial Intelligence: Governance and Ethics [Video]
ARTIFICIAL INTELLIGENCE | By James Maguire,
September 13, 2020 -
IBM Watson At The US Open: Showcasing The Power Of A Mature Enterprise-Class AI
FEATURE | By Rob Enderle,
September 11, 2020 -
Artificial Intelligence: Perception vs. Reality
FEATURE | By James Maguire,
September 09, 2020 -
Anticipating The Coming Wave Of AI Enhanced PCs
FEATURE | By Rob Enderle,
September 05, 2020 -
The Critical Nature Of IBM’s NLP (Natural Language Processing) Effort
ARTIFICIAL INTELLIGENCE | By Rob Enderle,
August 14, 2020
APPLICATIONS ARTICLES