With the continuing expansion of data mining by enterprises, it’s no longer possible or advisable for an organization to keep all data in a single location or silo. Yet having disparate data analytics stores of both structured and unstructured data, as well as Big Data, can be complex and chaotic.
Data virtualization is one increasingly common approach for dealing with the challenge of ever-expanding data. Data virtualization integrates data from disparate big data software and data warehouses – among other sources – without copying or moving the data. Most helpful, it provides users with a single virtual layer that spans multiple applications, formats, and physical locations, making data more useful and easier to manage.
Data virtualization often overlaps with data integration technologies, such as Extract, Transform and Load (ETL) tools, which all end up serving the same ultimate purpose: to collect data from different places and make it available for analysis or Business Intelligence (BI) purposes.
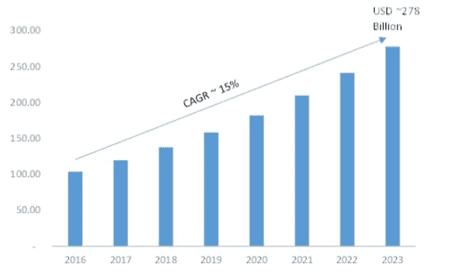
The market for data virtualization tools is expected to grow exponentially in the next few years – much like the overall data analytics market.
- How To Choose a Data Virtualization Tool
- Actifio Virtual Data Pipeline (VDP)
- Atscale Virtual Data Warehouse
- Data Virtuality Logical Data Warehouse
- Denodo
- IBM Cloud Pak for Data
- Informatica-PowerCenter
- Lyftron
- Oracle Data Service Integrator
- Red Hat JBoss Data Virtualization
- Stone Bond Enterprise Enabler
- TIBCO Data Virtualization
- Data Virtualization Vendor Comparison Chart
How To Choose a Data Virtualization Tool
The market for data virtualization tools is highly competitive, with multiple vendors and offerings. When looking to choose a data virtualization tool there are a number of criteria to consider.
- Applications. Consider what applications that will be consuming the data and make sure the data virtualization technology has the right type of integration.
- Performance. Data virtualization can come with a performance overhead that makes real time queries and data usage less than optimal. There are different ways that vendors optimize query performance to help enable more real time queries.
- Security and compliance. Consider the impact of data virtualization on existing security and compliance requirements and be sure to choose a solution that addresses those concerns.
In this Datamation top companies list, we spotlight the vendors that offer the top data virtualization tools.
- Actifio
- Atscale
- Data Virtuality
- Denodo
- IBM Cloud Pak for Data
- Informatica PowerCenter
- Lyftron
- Oracle Data Service Integrator
- Red Hat JBoss Data Virtualization
- TIBCO Data Virtualization
- Stone Bond Enterprise Enabler
- Data Virtualization vendor chart
Actifio Virtual Data Pipeline (VDP)
Value proposition for potential buyers. For organizations that need the reliability of an on-premises data virtualization solution, Actifio is a great choice. The company also offers a virtual cloud version, which is a fit for certain use cases.
Key values/differentiators:
- Actifio positions its Virtual Data Pipeline as an Enterprise Data-as-a-Service (EDaaS) platform. It powers both an on-premises hardware appliance as well as the Actifio Sky virtual edition that can be deployed as a software appliance on-premises or in the cloud.
- Simply virtualizing data isn’t enough, so what Actifio has is a form of application awareness that captures application data with methods that get the right data, for consistent point-in-time virtual images.
- The hardware appliance provides additional hardening, including access control and encryption for organizations that have the strictest compliance requirements.
- One of the key differentiators is the integrated rollback and recovery feature that can help correct issues with incorrect, lost or corrupted data.
Atscale Virtual Data Warehouse
Value proposition for potential buyers. Atscale’s Virtual Data Warehouse is a good choice for organizations that already have established data analytics processes, and that are looking to connect existing Business Intelligence tools to disparate sources of data, without the need to actually copy the data.
Key values/differentiators:
- Works with both on-premises and cloud-based data repositories, including traditional databases such as Microsoft SQL as well as cloud data warehouse services including Google BigQuery and Amazon Redshift.
- A key value is that there is no need for organizations to make use of an an ETL (Extract, Transform and Load ) process to make data usable as AtScale’s data abstraction engine removes the need for data to be copied or transformed.
- Integration with all of the major Business Intelligence applications is a big plus, even Microsoft Excel spreadsheets are supported, enabling users to access to data in a consistent secure way.
- Adaptive cache technology offers the promise of optimized query performance, delivering responses to queries in under five seconds as the system learns what users are asking and optimizes the performance of those queries in the underlying platform automatically.
Data Virtuality Logical Data Warehouse
Value proposition for potential buyers. Data Virtuality is a great fit for organizations with large data sets that cannot be easily virtualized with other solutions. Instead of just providing access through a virtual layer, the system can also replicate large data sets for faster query performance.
Key values/differentiators:
- Data across multiple sources can all be queried in a standardized way using SQL (Structured Query Language).
- Creates a logical data model from different data sources including databases and other sources of data such as Google Analytics.
- Connected data sources can be made available and combined via a Business Intelligence tool front end.
- For large data sets, Data Virtuality has an integrated analytical database that can replicate data, providing a faster query rate and better overall performance.
- Works as a Java based application server that can be hosted in the cloud or operated on-premises.
- The ability to very precisely pull data from an application, for example custom fields in Salesforce is seen as key differentiator by some users.
Denodo
Value proposition for potential buyers. Denodo is one of the best choices for organizations of any size looking to not just virtualize their data, but also understand what data they have.The data catalog feature that has emerged in the latest version of Denodo is a powerful feature for data virtualization users, offering the ability to not just combine and virtualize data but to identify and catalog data.
Key values/differentiators:
- Data catalogue feature in Denodo 7 enables organizations to use a semantic search query capability to find data as well as providing insights into how data is used by other users and applications.
- Parallel processing with query optimization capability minimizes network traffic load and can help to improve response times for large data sets.
- Integrated data governance capabilities are also particularly useful as they can help organization to managed compliance and data privacy concerns.
- For data usage, end users can choose to use SQL or other formats, including REST and OData to consume and secure data.
IBM Cloud Pak for Data
Value proposition for potential buyers. For organizations looking for a converged solution that handles data collection and analysis, IBM Cloud Pak for Data is a good choice. The offering was formerly known as IBM Cloud Private for Data and was rebranded in 2018.
Key values/differentiators:
- IBM Cloud Pak for Data is an integrated platform that enables organization to both collect and analyze data with the same platform.
- The core organizing concept for workflow is project based, with sophisticated controls for access and data governance for each activity.
- The user experience includes a drag and drop interface to connect data and perform complex ETL (Extract, Transform and Load) jobs to prepare data for analysis.
- IBM has also integrated an enterprise wide data catalogue to help users organize and identify the data they want to collect and analyze.
Informatica-PowerCenter
Value proposition for potential buyers. For organizations looking for a leading data virtualization tool with integrated data quality tools, PowerCenter is a solid choice. PowerCenter is consistently rated as a top data integration tool from analyst firms for its powerful set of features.
Key values/differentiators:
- Ease of use is a key attribute of PowerCenter, with a no-code based environment that uses a graphical user interface (GUI) to integrate nearly any type of data.
- A key element of the platform is the metadata manager which goes beyond just integrating data, to helping users with a visual editor that creates map of data flow across an environment.
- One of the most useful functions of PowerCenter is the impact analysis feature, which can identify the impact to an enterprise about a data integration effort before any changes are actually implement.
- It can happen that a data integration or data virtualization activity breaks something, which is why PowerCenter’s data validation capabilities are so critical. The data validation capability is there to make sure that data has not been damaged by a move or transformation.
- Data archiving is another really useful feature, that enables organizations to move and compress data out of older applications that are not actively used.
Lyftron
Value proposition for potential buyers. The Lyftron solution offers data virtualization, logical data warehouses and – particularly important – self service data preparation, with the goal of providing an easier and faster solution.
- The platform manages a unified data set-up to enable security monitoring that is centralized for efficiency and ease of use.
- Lyftron touts its ability to offer a universal abstraction over virtually any data source, which allows data virtualization to enable staffers to mine data without worrying about the challenges of data type and format.
- The solution is geared for hybrid cloud management and migration, allowing companies to construct a cloud-based data warehouse that connects today’s top public cloud vendors. Users can then mine the data – instantly – that resides in all of these disparate locations.
- Lyftron’s logical data warehouse technology offers parallel access to all data source in one centralized location.
Oracle Data Service Integrator
Value proposition for potential buyers. For those organizations that are already making use of other Oracle applications for data storage and analytics, Oracle Data Service Integrator is an obvious and easy choice to make for data virtualization.
Key values/differentiators:
- Among the more unique features is that Oracle Data Service Integrator can both read and write data from multiple sources, enabling this tool to be used for a variety of different use-cases.
- Service integration is done via a graphical modelling capability, so users don’t need to code the integration manually.
- Security is a key feature with rules-based security policies to make sure that certain data elements are protect, or redacted to help meet various privacy and compliance needs.
- Going a step further on the security side, Oracle has also integrating sophisticated auditing, that keep track of users and what data was accessed and when.
- Real-time access to data is a particular strength, thanks to optimized query and data patch technology that Oracle has baked into this offering.
Red Hat JBoss Data Virtualization
Value proposition for potential buyers. Red Hat Data Virtualization is a good choice for developer-led organizations and those that are using microservices and containers, to build and enable a virtual data layer that abstracts disparate data sources.
Key values/differentiators:
- The abstraction layer that Red Hat creates with Data Virtualization, creates what in effect becomes a virtual database that can be consumed via a standard interface.
- The platform provides graphical user interface tooling that is based on the Eclipse Integrated Developer Environment (IDE), making it easier for developers to make use of existing tools and skills.
- Red Hat has a particular focus on microservices and containers, which is reflected in the latest version of JBoss Data Virtualization with capabilities that make it simpler for developers to connect their microservices with the virtual data layer backend.
- Of note is the platform’s integration with the Red Hat JBoss Data Grid, which can optionally be used to provide an in-memory database cache to accelerate lookups and overall performance.
Stone Bond Enterprise Enabler
Value proposition for potential buyers. The Enterprise Enabler solution, available on AWS, is a versatile data tool – fully capable of data virtualization – that can handle hybrid or multicloud environments.
- Suitable for SMB or large enterprise, Enterprise Enabler is available in three different bundles (3 data source, 6 data sources, or Bring Your Own License) which offers significant flexibility for customers.
- Though based in Texas, Stone Bond has a number of European and South American offerings for customers.
- To the company’s credit, Stone Bond is focused on offering a diverse array of deployment configurations. Hosting the solution on AWS enables users to change and track usage parameters as business needs change. In some scenarios, this allows the possibility that higher priced hardware infrastructure will no longer be needed.
- Stone Bond is fully focused on data virtualization, not as a sideline but as a core offering.
TIBCO Data Virtualization
Value proposition for potential buyers. TIBCO acquired the data virtualization application technology from Cisco in 2017 and has steadily improved it in the years since then. The ability to easily enable data to be used in other applications is a key capability.
Key values/differentiators:
- The system is able to look at data and discovers relationships, helping administrators and users to build a virtual data layer from multiple types of data sources.
- For non relational and unstructured data sources, TIBCO provides a built-in transformation engine to join data together.
- Of particular note is the interface, which enables business users to select from a data directory to build views for data. It’s a different take on the data catalogue idea and one that some users really tend to like.
- As part of the offering, TIBCO enables virtualized data to be made available as a data service using auto-generated WSDL (Web Services Description Language) descriptors.
Data Virtualization Vendor Comparison Chart
|
Vendor/Product |
Key Features |
Differentiators |
|
Actifio |
Both physical and virtual deployment options.
Application aware data. |
Integrated rollback and recovery. |
|
Atscale |
Adaptive cache technology for optimized query performance.
Works well with both on-premises and cloud based data repositories and warehouses.
|
Lots of integration options with Business Intelligence tools.
|
|
Data Virtuality |
SQL-based data query.
Data replication capability for large data sets that can’t be easily virtualized.
|
Precise data filed level collection and virtualization from data sources. |
|
Denodo |
Data governance for compliance and privacy.
Semantic search query capability. |
Data catalog features that helps users to find the right data for analysis. |
|
IBM Cloud Pak for Data |
Drag and drop interface for ETL transactions
Integrated workflow controls for analysis and data governance. |
Converged solution for both data virtualization and analyze. |
|
Informatica-PowerCenter |
Impact analysis for data integration efforts. GUI for data modelling. |
Integrated data quality tools. |
|
Lyftron |
Abstracts virtually any data source Adapt at hybrid cloud management. |
Self Service data prep.
|
|
Oracle Data Service Integrator |
Real-time data access.
Ability to both read and write data from multiple sources. |
Rules-based security policies to make sure that certain data elements are protect, or redacted to help meet various privacy and compliance needs. |
|
Red Hat JBoss Data Virtualization |
Virtual database abstraction layer can be access via a standard interface.
Integration with JBoss Data Grid for accelerated lookups. |
Integration with Kubernetes and container based environments. |
|
Stone Bond Enterprise Enabler |
Works with hybrid or multicloud environments.
Suitable for SMB or large enterprise. |
Company is deeply focused on data virtualization. |
|
TIBCO Data Virtualization |
Business directory of data to help users with analysis
Built-in transformation engine for unstructured data sources. |
Ability to create data services from virtualized data. |
BIG DATA ARTICLES