

Data warehouses are repositories where large amounts of data can be stored and accessed for reporting, business intelligence (BI), analytics, decision support systems (DSS), research, data mining, and other related activities. While they’re always associated with large amounts of data, data warehouses are not simply about massive storage capacity—rather, they’re about making disparate types of data from many different sources accessible to support decision-making. This article explains the concept of data warehouses, explores their construction and uses and explains how they differ from other types of large-scale data storage.
What is a Data Warehouse?
A data warehouse is a storage architecture to support the retention and access of large amounts of data used for a variety of decision-making purposes. They are optimized to retain and process large amounts of data fed into them via online transactional processing (OLTP)—a type of data processing that executes many concurrent transactions as in online banking, shopping, or text messaging, for example— and other high volume systems. This data can then be used for reporting, search, and analysis.
Data warehouses are designed to ease the function of analytics by bringing together data from disparate sources into a central repository where rapid analysis can be carried out. Otherwise, data scientists and analysts have to extract the data they want to analyze from different sources and bring it into an application for analysis.
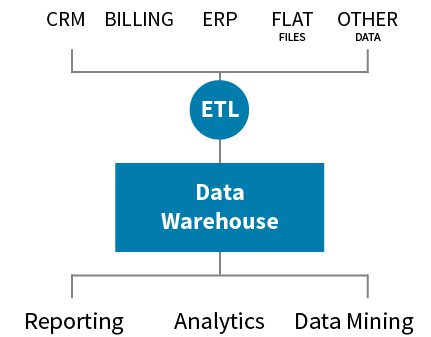
A data warehouse can gather data from many different sources—including traditional relational databases, transactional systems, and large swaths of unstructured data from multiple sources—where it can be accessed by BI, analytics, and artificial intelligence (AI) applications for prediction, decision-making, and evaluation.
How are Data Warehouses Constructed?
Data warehouses are optimized to deal with large volumes of data. While most are kept in the cloud, some are still kept on mainframe systems and enterprise-class servers. Data from OLTP applications and other sources is extracted for queries and used by analytical applications.
Data warehouses can be designed to receive and process different types of data, with data volume, frequency, retention periods, and other factors determining the specifics of construction. Business goals and objectives lead the design, which is then focused on collecting, normalizing, and cleaning the relevant data.
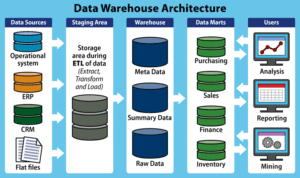
Perhaps the most vital aspect of design is the underlying storage infrastructure. Storage media must be capable of hosting a large quantity of data—if it’s cloud-based, the appropriate storage tier should be chosen to meet the needs, balancing cost, capacity, and price. Flash media offers the highest performance, for example, but at the highest cost. Hard disk drives (HDDs) offer better capacity for cost, while hybrid flash/HDD solutions can boost performance without breaking the bank, making it possible for analytics systems to move needed data into flash for faster processing.
Some data warehouse architecture is designed primarily to cope with structured data from relational databases. As most modern data warehouses collect and store data from both the cloud and on-premises systems, they must be set up to cope well with both structured and unstructured data like emails, text messages, and multimedia.
What are Data Warehouses Used For?
As a central repository for an organization’s business information, a data warehouse can incorporate disparate databases, systems, and processes to facilitate the presentation of a unified and integrated approach to organizing data for better access and easy interpretation.
Data warehouse tools make it possible to manage data more efficiently. This includes being able to more easily find, access, visualize and analyze data in order to achieve better business results. Other systems use data warehouses to generate reports and dashboards, making them useful across an organization.
More than yet another tool, the data warehouse is a central element in any Big Data infrastructure.
As enterprises increasingly realize the potential value of the data they have gathered over many years, they’ve begun to recognize the value of the data warehouse—especially when they consider how much of their data is unstructured. The ability to gather that information together and subject it to analysis or make it available for search makes data warehouses indispensable to businesses.
Learn more about data warehouse tools and solutions.
Data Warehouse Types
Generally speaking there are three main types of data warehouses: enterprise, operational, and data mart.
Enterprise Data Warehouse
An enterprise data warehouse is an architecture designed specifically to support the needs of an entire business, bringing together data from a multitude of organizational sources in centralized storage to support decision-making and analysis.
Operational Data Store (ODS)
Operational data stores are data warehouses set up to facilitate reporting or highly specialized analysis. These are smaller than enterprise-grade architectures, and easier to set up. They refresh in real time and are preferred for day-to-day activities that don’t support reporting needs, like storing employee records.
Data Mart
This subcategory of data warehouse is used to serve a specific line of business, such as finance, sales, or HR. By collecting all that data in a smaller repository—or within a confined section of the overall data warehouse—it supports functions that require faster answers, quicker searches, and more focused analysis of limited data sets.
Database vs. Data Warehouse
The difference between a database and a data warehouse is simple—databases deal entirely with structured data. The data is clearly-defined and organized within a very specific structure, such as columns and rows, and each record must include entries for required fields. While this requires more rigorous data entry, it makes it possible to process huge volumes of transactions rapidly.
A data warehouse, on the other hand, is more loosely defined and can accept data from multiple sources and disparate formats. It stores both current and historical data of all times in a centralized location accessible to data scientists and business analysts.
Data Lake vs. Data Warehouse
Both data lakes and data warehouses are repositories for large volumes of data, but there is a key difference between them—data lakes store raw data, while a data warehouse involves processing to clean and consolidate the data before it is stored. While both provide actionable insights, a data warehouse is a combination of technologies designed to transform data into information.
Benefits of a Data Warehouse
Aside from the obvious benefit of a data warehouse—the ability to host a very large amount of data—there are additional advantages to using them. Because they store the historical, unstructured data that can otherwise clutter high-performance databases, enterprises can use them to free up space for more immediate organizational needs. Multiple databases can feed one large data warehouse and offload data to it as needed.
Data warehouses also make it possible to translate data into information and insight by offering an effective way to support queries, analytics, reporting, and modeling, as well as forecasting and trending against larger amounts of data and time.
Disadvantages of Data Warehouses
While the disadvantages of a data warehouse often comes down to the specific architecture and design, a few common challenges stand out.
Some data warehouses don’t deal with unstructured data as well as others, and those that don’t essentially omit analysis of an entire field of information. While modern data warehouses are designed to handle both structured and unstructured data, it’s not uncommon for vendors to build them on aging infrastructure and focus them on more traditional data formats.
Cost can also be a disadvantage. As the volume of enterprise data continues to grow at an estimated 30 percent annually, data warehouses may become cost prohibitive and force companies to shift to the more affordable raw data storage of a data lake.
A Single Source Of Truth
The original intent of the data warehouse architecture was to create a single source of truth in an enterprise—a goal that remains elusive. Because the data being fed into the warehouse typically comes from other sources, including Enterprise Resource Planning (ERP), customer relationship management, and human resources systems, it’s difficult to easily consolidate it into a single source of accurate data.
Additionally, mergers and acquisitions among business and vendors can pose obstacles to consolidating multiple data warehouses and disparate architectures into something that offers a unified answer to queries.
Bottom Line: The Future of Data Warehouses
Data management techniques, platforms, and approaches are constantly evolving, and what this might mean for the data warehousing industry remains to be seen. Traditional databases were sufficient for organizational needs for many decades, but as new formats emerged and the volume of data escalated, it stopped being viable to manage data solely inside relational systems. Data warehouses emerged as a solution to that problem—but will it be up to the task for the next one?
As the sheer quantity of unstructured data collected and used by enterprises continues to scale, data warehouses may not be the right solution for every business data storage need. Instead, it’s likely that they’ll become the de facto architecture for some types of information, while the popularity of data lakes as the solution for others grows—and entirely new solutions may emerge to replace them both. For now, data warehouses meet the needs of most enterprises looking to store and analyze large volumes of data in a solution that meets the balance between capacity, performance, and cost.
To learn more about how enterprises are overcoming the difficulties of dealing with vast amounts of data, read Data Management: Types and Challenges.