

Data integration, which combines data from different sources, is essential in today’s data-driven economy because business competitiveness, customer satisfaction and operations depend on merging diverse data sets. As more organizations pursue digital transformation paths – using data integration tools – their ability to access and combine data becomes even more critical.
How Data Integration Works
As data integration combines data from different inputs, it enables the user to drive more value from their data. This is central to Big Data work. Specifically, it provides a unified view across data sources and enables the analysis of combined data sets to unlock insights that were previously unavailable or not as economically feasible to obtain. Data integration is usually implemented in a data warehouse, cloud or hybrid environment where massive amounts of internal and perhaps external data reside.
In the case of mergers and acquisitions, data integration can result in the creation of a data warehouse that combines the information assets of the various entities so that those information assets can be leveraged more effectively.
Types of Data Integration Tools Available Today
Data integration platforms integrate enterprise data on-premises, in the cloud, or both. They provide users with a unified view of their data, which enables them to better understand their data assets. In addition, they may include various capabilities such as real-time, event-based and batch processing as well as support for legacy systems and Hadoop.
Although data integration platforms can vary in complexity and difficulty depending on the target audience, the general trend has been toward low-code and no-code tools that do not require specialized knowledge of query languages, programming languages, data management, data structure or data integration.
Importantly, these data integration platforms provide the ability to combine structured and unstructured data from internal data sources, as well as combine internal and external data sources. Structured data is data that’s stored in rows and columns in a relational database. Unstructured data is everything else, such as word processing documents, video, audio, graphics, etc.
In addition to enabling the combination of disparate data, some data integration platforms also enable users to cleanse data, monitor it, and transform it so the data is trustworthy and complies with data governance rules.
Types of data integration tools include:
- ETL platforms that extract data from a data source, transform it into a common format, and load it onto a target destination (may be part of a data integration solution or vice versa). Data integration and ETL tools can also be referred to synonymously.
- Data catalogs that enable a common business language and facilitate the discovery, understanding and analysis of information.
- Data governance tools that ensure the availability, usability, integrity and security of data.
- Data cleansing tools that identify, correct, or remove incomplete, incorrect, inaccurate or irrelevant parts of the data.
- Data replication tools capable of replicating data across SQL and NoSQL (relational and non-relational) databases for the purposes of improving transactional integrity and performance.
- Data warehouses – centralized data repositories used for reporting and data analysis.
- Data migration tools that transport data between computers, storage devices or formats.
- Master data management tools that enable common data definitions and unified data management.
- Metadata management tools that enable the establishment of policies and processes that ensure information can be accessed, analyzed, integrated, linked, maintained and shared across the organization.
- Data connectors that import or export data or convert them to another format.
- Data profiling tools for understanding data and its potential uses.

Data Integration: Related Approaches
Data integration started in the 1980’s with discussions about “data exchange” between different applications. If a system could leverage the data in another system, then it would not be necessary to replicate the data in the other system. At the time, the cost of data storage was higher than it is today because everything had to be physically stored on-premises since cloud environments were not yet available.
Exchanging or integrating data between or among systems has been a difficult and expensive proposition traditionally since data formats, data types, and even the way data is organized varies from one system to another. “Point-to-point” integrations were the norm until middleware, data integration platforms, and APIs became fashionable. The latter solutions gained popularity over the former because point-to-point integrations are time-intensive, expensive, and don’t scale.
Meanwhile, data usage patterns have evolved from periodic reporting using historical data to predictive analytics. To facilitate more efficient use of data, new technologies and techniques have continued to emerge over time including:
Data warehouses. The general practice was to extract data from different data sources using ETL, transform the data into a common format and load it into a data warehouse. However, as the volume and variety of data continued to expand and the velocity of data generation and use accelerated, data warehouse limitations caused organizations to look for more cost-effective and scalable cloud solutions. While data warehouses are still in use, more organizations increasingly rely on cloud solutions.
Data mapping. The differences in data types and formats necessitated “data mapping,” which makes it easier to understand the relationships between data. For example, D. Smith and David Smith could be the same customer and the differences in references would be attributable to the applications fields in which the data was entered.
Semantic mapping. Another challenge has been “semantic mapping” in which a common reference such as “product” or “customer” holds different meaning in different systems. These differences necessitated ontologies that define schema terms and resolve the differences.
Data modeling. Data modeling has also evolved to minimize the creation of information silos. More modern data models take advantage of structural metadata (data that describes data). The resulting standardized entities can be used by multiple data models, enabling integrated data models. When instantiated as databases, the integrated data models are populated using a common set of master data enabling integrated databases.
Data lakes. Meanwhile, the explosion of Big Data has resulted in the creation of data lakes that store vast amounts of raw data.
Examples of Data Integration
The explosion of enterprise data coupled with the availability of third-party data sets enables insights and predictions that were too difficult, time consuming, or practical to do before. For example, consider the following use cases:
- Companies combine data from sales, marketing, finance, fulfillment, customer support and technical support – or some combination of those elements – to understand customer journeys.
- Public attractions such as zoos combine weather data with historical attendance data to better predict staffing requirements on specific dates.
- Hotels use weather data and data about major events (e.g., professional sports playoff games, championships, or rock concerts) to more precisely allocate resources and maximize profits through dynamic pricing.
Theory
Data integration theories are a subset of database theories. They are based on first-order logic, which is a collection of formal systems used in mathematics, philosophy, linguistics and computer science. Data integration theories indicate the difficulty and feasibility of data integration problems.
Importance
Data integration is necessary for business competitiveness. Still, particularly in established businesses, data remains locked in systems and difficult to access. To help liberate that data, more types of data integration products have become available. Liberating the data enables companies to better understand:
- Their operations and how to improve operational efficiencies.
- The competitors.
- Their customers and how to improve customer satisfaction/reduce churn.
- Partners.
- Merger and acquisition targets.
- Their target markets and the relative attractiveness of new markets.
- How well their products and services are performing and whether the mix of products and services should change.
- Business opportunities.
- Business risks.
Other benefits of data integration include:
- More effective collaboration.
- Faster access to combined data sets than traditional methods such as manual integrations.
- More comprehensive visibility into and across data assets.
- Data syncing to ensure the delivery of timely, accurate data.
- Error reduction as opposed to manual integrations.
- Higher data quality over time.
Data Integration Versus Data Warehouse
Data integration combines data but does not necessarily result in a data warehouse. It provides a unified view of the data; however, the data may reside in different places.
Data integration results in a data warehouse when the data from two or more entities is combined into a central repository.
Data Integration Challenges
While data integration tools and techniques have improved over time, organizations can nevertheless face several challenges which can include:
- Data created and housed in different systems tends to be in different formats and organized differently.
- Data may be missing. For example, internal data may have more detail than external data or data residing in a mainframe may lack time and data information about activities.
- Historically, data and applications have been tightly-coupled. That model is changing. Specifically, the application and data layers are being decoupled to enable more flexible data use.
- Data integration isn’t just an IT problem; it’s a business problem.
- Data itself can be problematic if it’s biased, corrupted, unavailable, or unusable (including uses precluded by data governance).
- The data is not available at all or for the specific purpose for which it will be used.
- Data use restrictions – whether the data be used at all, or for the specific purpose.
- Extraction rules may limit data availability.
- Lack of a business purpose. Data integrations should support business objectives.
- Service-level integrity falls short of the SLA.
- Cost – will one entity bear the cost or will the cost be shared?
- Short-term versus long-term value.
- Software-related issues (function, performance, quality).
- Testing is inadequate.
- APIs aren’t perfect. Some are well-documented and functionally sound, while others are not.
How to Implement Data Integration
Organizations should make a point of articulating their short-term and long-term integration goals because as requirements grow, scaling can become a problem. Business requirements and software requirements both deserve consideration to help ensure that investments advance business objectives and to minimize technical setbacks.
Data integration implementations can be accomplished in several different ways including:
- Manual integrations between source systems.
- Application integrations that require the application publishers overcome the integration challenges of their respective systems.
- Common storage integration data from different systems is replicated and stored in a common, independent system.
- Middleware which transfers the data integration logic from the application to a separate middleware layer.
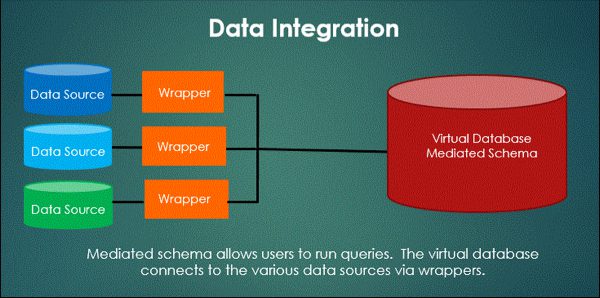
- Virtual data integration or uniform access integration, which provide views of the data, but data remains in its original repository.
- APIs which is a software intermediary that enables applications to communicate and share data.
BIG DATA ARTICLES