

Generally speaking, data can be classified into two types: structured and unstructured. Structured data exists in a fixed record format, making it highly organized and easy to search. For example, think of customer contact information—first name, last name, phone number—stored in a database with each field labeled. Unstructured data, on the other hand, includes things like multimedia files, emails, and text messages that might contain lots of useful information but are more difficult to search and use.
As enterprises become increasingly reliant upon data to fuel operations and inform decision-making, the challenge is not a matter of structured data vs. unstructured data—it’s how to gather, store, and process both types. This article explores the differences between structured and unstructured data and how companies can use each to their benefit.
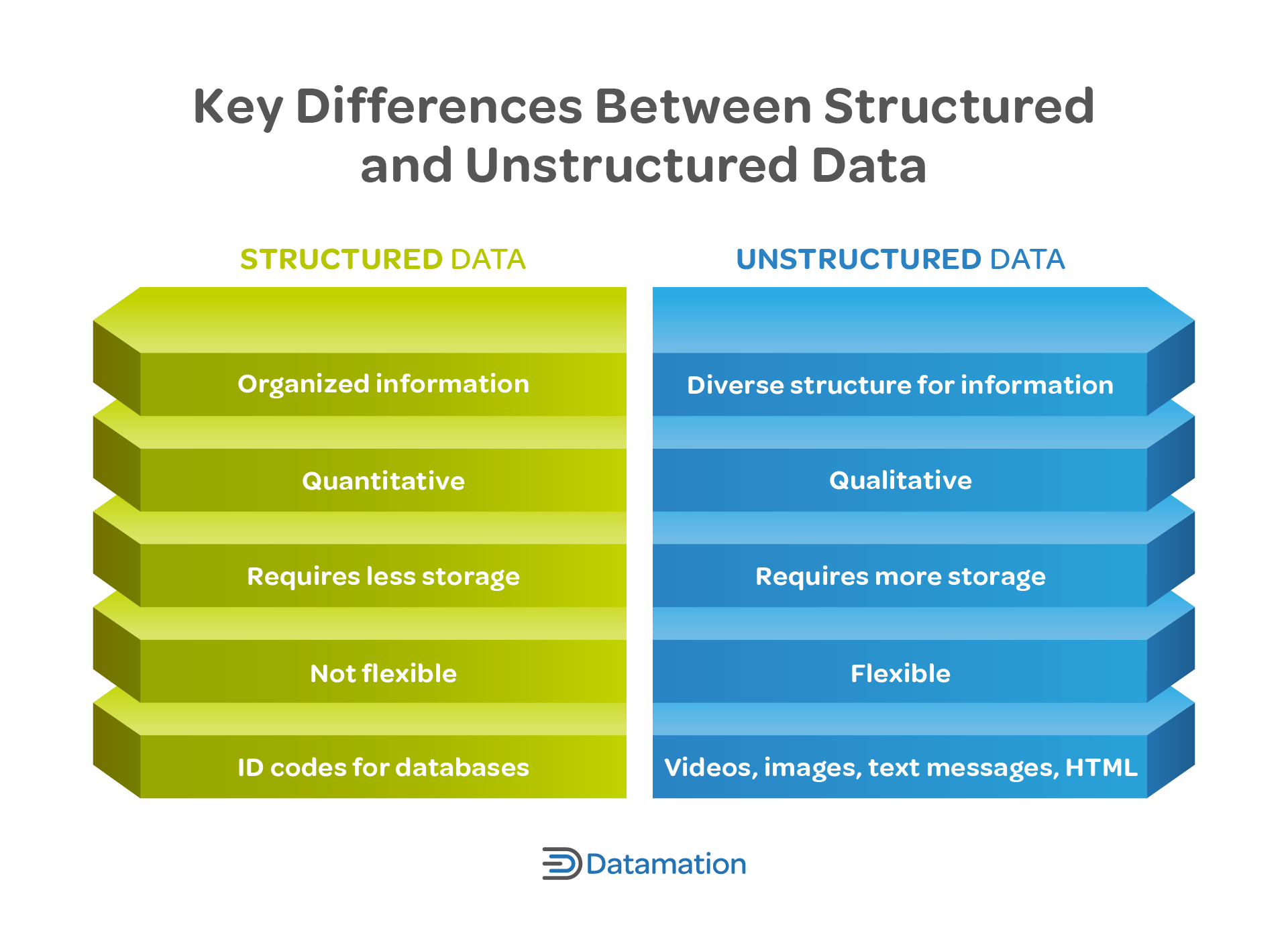
Key Differences Between Structured and Unstructured Data
The key to understanding structured data lies in its name—it follows a specific format and organization, making it easier for machines to read and process data. This structure is usually predefined and consistent, meaning it uses the same format across all instances of the data. Unstructured data is information with no formal structure, which makes it more difficult to label and search.
The following chart shows the differences between structured and unstructured data at a high level.
To some degree, most data is a hybrid of unstructured and structured data. Semi-structured data is a loosely defined subset of structured data. Think of it as unstructured data to which tags, keywords, and metadata have been added to make it more useful—for example, descriptive elements to images, emails, and word processing files.
What is Structured Data?
Structured data, or quantitative data, is information that’s highly organized and readable by machine learning algorithms, making it easier to search, manipulate, and analyze. You’ll typically find structured data in database tables, rows, and columns. Each field contains a specific type of data corresponding to its category and value.
Think of a spreadsheet with specific headings for each column. This format makes it possible for search engine algorithms to read and understand data. Structured data can include names, addresses, and dates, for example—easily recognizable and clear fields. Because every record has a search key, and every field within those records is clearly delineated, you can search these records and data fields using standard database searches or analytics programs.
Additionally, because structured data is highly organized, people and automated tools can quickly scan, organize, and analyze vast amounts of it.
Structured Data Sources
Structured data can be generated in a number of ways, and from a number of sources. It can come from enterprise software such as customer relationship management (CRM) systems, accounting programs, and other applications used in critical business operations. It can be generated from online sources, including social media platforms and web-based surveys. It can also come from manual human input.
In addition, structured data can be extracted from unstructured data using business intelligence (BI) tools that rely on artificial intelligence (AI) and natural language processing (NLP).
What is Unstructured Data?
Unstructured data is information with no inherent structure or organization. Pieces of unstructured data are generically referred to as “objects” because they have no no record keys to identify them. In order to organize and identify unstructured object data, each separate unstructured object must be labeled with a “tag” or identifier so it can be searched and located.
Examples of unstructured data include videos, emails, images, and HTML content. This kind of data makes up between 80 and 90 percent of all data generated globally, but it’s considerably less valuable than structured data as it’s much more difficult to handle and extract insights from.
Unstructured Data Sources
Unstructured data comes from a wide range of sources. An unstructured data object can be freeform text that is not broken down into a fixed record format containing individual data fields. Unstructured data can also come in the form of a photo, video, engineering CAD drawing, social media text stream, HTML document, or any form of data that is not captured as a fixed record, field-defined data format.
Unstructured data can sometimes be found within structured data records. For example, consider a form that offers questions with a dropdown list of answers that also allows users to add free-form comments—answers generated from the pick list are structured data, but the comments field yields unstructured data.
What is Semi-Structured Data?
Semi-structured data occupies the middle ground between structured and unstructured data as data that has some degree of organization but is not fully organized into a fixed record format found in a traditional system or database.
For example, you could add some structure to a natively unstructured XML document using metadata to explain who created the document and when, and keywords to describe the content and make it possible to be found in searches. In the case of HTML documents, which would otherwise be unstructured, H1 tags are used to identify their titles while H2 identify subsections, making it more easily searchable.
Semi-Structured Data Sources
Semi-structured data comes in many formats from a wide variety of sources. Internet of Things (IoT) sensors generate massive amounts of data—they might be used in shipping warehouses, for example, to optimize order fulfillment, or in manufacturing to monitor equipment health and functionality. Much of this data can be made more useful by adding tags that make it searchable.
Markup languages like HTML and XML are also a common source for semi-structured data. While it is less efficient to search through tagged semi-structured data than structured data, tagging can help sites and technologies like AI to identify and retrieve documents and other unstructured data objects in searches.
How do Companies use Structured and Unstructured Data?
Today’s enterprises find themselves in an unusual situation, with around 80 percent of their day-to-day IT processing done using traditional structured data while 80 percent of incoming new data is unstructured. This reality demands that, from a data management standpoint, companies must take a hybrid approach to data that includes ways to manage and process both unstructured and structured data.
The quickest route to universal data management is to ensure that all unstructured data objects are tagged—in essence, made semi-structured—so they can be individually identified and searched.
Data tagging is also a requirement for organizations that want to link or combine both structured and unstructured data into a composite, hybrid data record—for example, linking a photo of a lawnmower to a fixed record description of the item in a sales catalog record file, or appending a company employee ID badge to that employee’s fixed record description in a human resources system.
The ability to process structured, unstructured, and unstructured-but-tagged data becomes increasingly essential as businesses shift more work into analytics and AI systems.
The Bottom Line
Todays’ companies must use a hybrid data management approach if they are to successfully manage, store, curate, and make use of the vast troves of data available to them. This hybrid approach is characterized by an ability to use both structured and unstructured data in daily IT operations, with data mining options that are able to find and link these variegated types of data to each other.
The key to this hybrid data management approach is semi-structured data, or unstructured data that has been identified and tagged to render it more useful by turning it into a kind of structured data.
To learn more about some of the software enterprises use to work with vast amounts of data, read Top 7 Data Modeling Tools You Need to Know in 2023.