

Data quality tools are an essential part of an organization’s data software stack. These tools help organizations import data from a variety of sources; understand and parse the data they are collecting; validate, standardize, clean, and match data; enrich the data with additional information; and detect any errors and data quality issues that arise. While some data analytics platforms have data cleansing and transformation functions built into their systems, others rely on specialized data quality tools to prepare the data for analysis.
We compared the most popular data quality tools on how well they met enterprise requirements for pricing, core features, customer support, data management features, and security. The following are our picks for the seven best data quality tools and platforms available today:
- Ataccama ONE: Best for working with big data
- Data Ladder: Best for managing and enhancing address data
- DQLabs Data Quality Platform: Best for automation
- Informatica Intelligent Data Management Cloud: Best for data integrations
- Precisely Data integrity Suite: Best for responsive customer support
- SAS Data Quality: Best for collaboration
- Talend Data Fabric: Best for understanding your data reliability
- Top Data Quality Tool Comparison
- Ataccama ONE
- Data Ladder
- DQLabs Data Quality Platform
- Informatica Intelligent Data Management Cloud
- Precisely Data Integrity Suite
- SAS Data Quality
- Talend Data Fabric
- Key Features of Data Quality Tools
- How to Choose the Best Data Quality Tool for Your Business
- How We Evaluated Data Quality Tools
- Frequently Asked Questions (FAQs)
- Bottom Line: Enterprise Data Quality Tools
Top Data Quality Tool Comparison
All of the data quality tools we explored provided a full range of data cleansing and transformation functions. Differentiators included the level of automation the tools support, the depth of the data management functionality, and pricing.
| Data Cleaning & Transformation | Automation | Data Management | Support | Annual Pricing | |
|---|---|---|---|---|---|
| Ataccama ONE | Yes; plug-in modules connect to third-party systems for data enrichment | Yes | Yes; impact analysis not automated |
|
|
| Data Ladder | Yes; Data enrichment via third-party sources | Limited | No |
|
|
| DQLabs Data Quality Platform | Yes; Some functions only available at higher subscription tiers | Yes | Yes, but impact analysis only available at higher subscription tiers |
|
|
| Informatica Intelligent Data Management Cloud | Yes | Yes | Yes |
|
|
| Precisely Data Integrity Suite | Yes | Yes | Yes; no root cause analysis or impact analysis available |
|
|
| SAS Data Quality | Yes | Yes | Yes |
|
|
| Talend Data Fabric | Yes; data enrichment via third-party sources | Limited | Limited; some functions require add-on software |
|
|
Jump to:
- Key Features of Data Quality Tools
- How to Choose the Best Data Quality Tools for your Business
- How we Evaluated Data Quality Tools
- Frequently Asked Questions (FAQ)
- Bottom Line
![]()
Ataccama ONE
Best for working with Big Data
Overall Rating: 4/5
- Cost: 2.4/5
- Core Features: 4.75/5
- Support: 3.5/5
- Data Management: 4.65/5
- Security: 5/5

Ataccama ONE is an enterprise-grade modular platform that combines a full set of data quality features with data governance and data management capabilities. The tool can be deployed as a cloud-based solution, on-premises, or in a hybrid environment.
Visit AtaccamaPricing
- Vendor does not provide pricing information
- Starts at $90,000 per year on the Azure Marketplace
- Ataccama’s data quality tool is available as a free download
Features
- AI-enhanced data quality tools
- Anomaly detection and alerts
- Data catalog and governance tools
| Pros | Cons |
|---|---|
| Runs natively on nine most common big data platforms | Complex to learn for non-technical users |
| Automated detection and rules assignment | Implementation can be lengthy and complicated |
| Responsive customer support |
![]()
Data Ladder
Best for managing and enhancing address data
Overall Rating: 2.3/5
- Cost: 1.25/5
- Core Features: 3.9/5
- Support: 3.5/5
- Data Management: n/a
- Security: 3.5/5
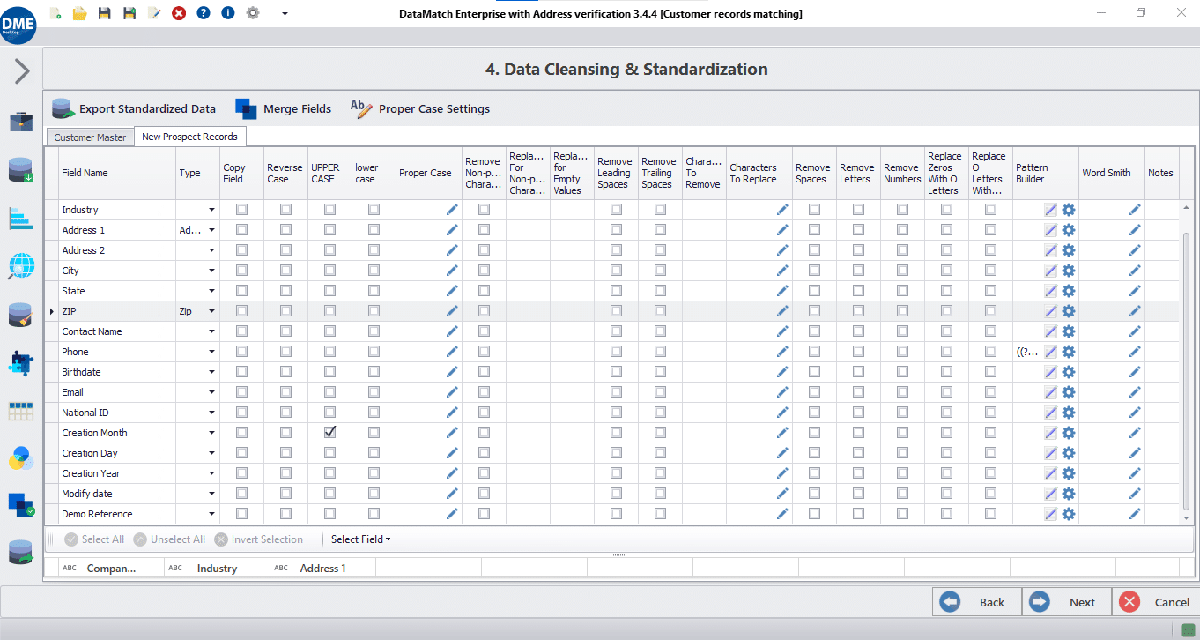
Data Ladder is a specialized data quality and matching tool used by a wide range of businesses to profile, clean, and transform customer data. Since it does not include data management and governance functionality, it is less costly than most of the other systems reviewed here. The tool includes a built-in USPS database to ensure consistency in address formats.
Visit Data LadderPricing
- Vendor does not provide pricing information
- 30-day free trial available
Features
- Data profile reports
- High-quality data matching
- Address verification
- Match and classify product data
| Pros | Cons |
|---|---|
| Can link records across datasets | Limited automation options |
| Fuzzy logic matching | No data management or governance functions |
![]()
DQLabs Data Quality Platform
Best for automation
Overall Rating: 3.65/5
- Cost: 1.75/5
- Core Features: 4./5
- Support: 3.25/5
- Data Management: 4.65/5
- Security: 4.4/5
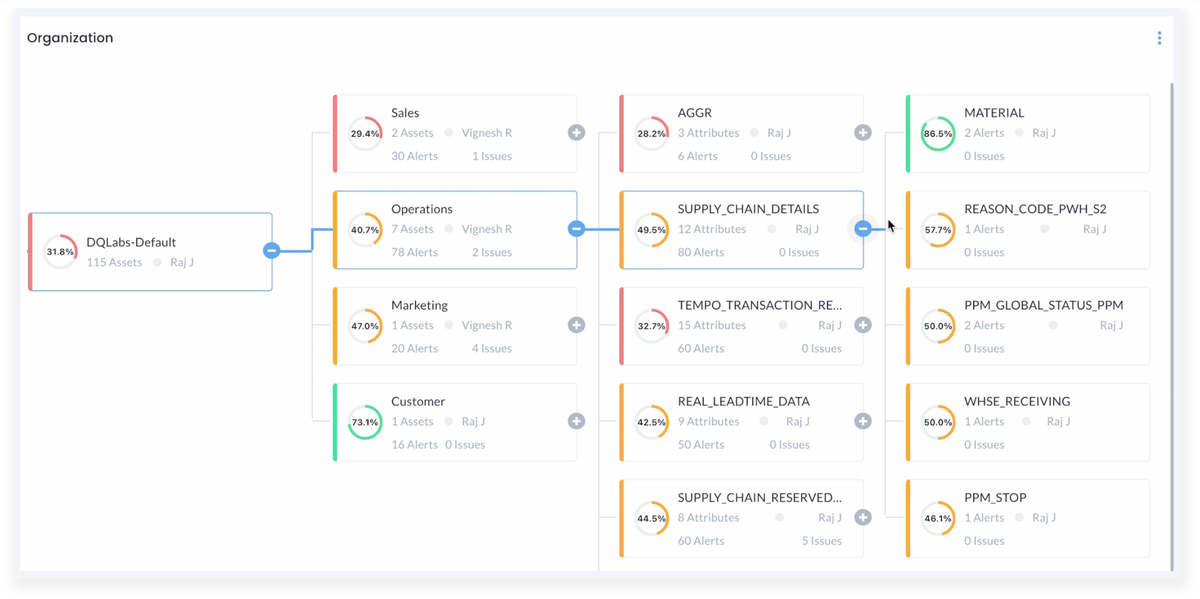
DQLabs Data Quality Platform takes an automation-first approach to data quality, harnessing machine learning to perform quality checks on data without the need for extensive coding. Its user-friendly interface is accessible to non-technical users as well as data engineers, and its data observability tools facilitate data governance activities.
Visit DQLabsPricing
- Three tiers of service; pricing provided by custom quote
- Free trial available
Features
- Automated incident detection
- Pre-built connectors to data sources
- Auto-discovery of business rules
| Pros | Cons |
|---|---|
| Easy-to-use graphical user interface | The product is still fairly new to the market and is continuing to develop |
| Integration with Slack, Microsoft Teams, and Jira to deliver real-time alerts and notifications | |
| Responsive to customer feedback |
![]()
Informatica Intelligent Data Management Cloud
Best for data integrations
Overall Rating: 4.5/5
- Cost: 2.9/5
- Core Features: 5/5
- Support: 4.75/5
- Data Management: 5/5
- Security: 5/5
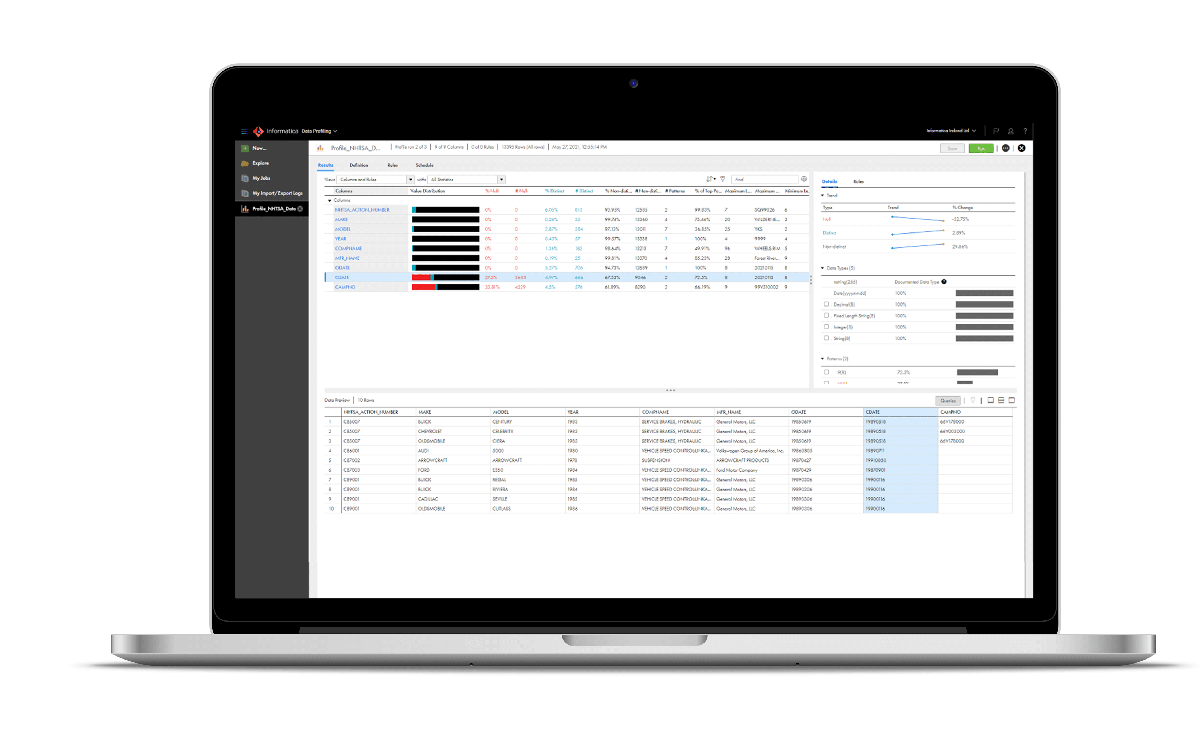
A cloud-native solution, Informatica Intelligent Data Management Cloud offers thousands of connectors and integrations to data sources and apps, making it easy and fast to ingest data from nearly any source on the web. The platform’s CLAIRE AI engine facilitates data matching and rule creation, reducing the time it takes to classify data and making it faster to find actionable insights. Its data catalog and Master Data Management tools allow for ongoing monitoring and governance of your business data.
Visit InformaticaPricing
- Vendor does not provide pricing
- Subscriptions are based on a package of processing units, which provides access to platform
- Starts at $129,600 per year on the AWS Marketplace
- 30-day free trial available
Features
- Data profiling, cleansing, and standardization tools
- Automated data discovery
- Data sharing across teams via a data marketplace
| Pros | Cons |
|---|---|
| Ability to use any tool in the platform without added costs | The platform is one of the more expensive offerings on the market |
| User-friendly interface | |
| Easy data sharing |
![]()
Precisely Data Integrity Suite
Best for responsive customer support
Overall Rating: 3.3/5
- Cost: 0/5
- Core Features: 5/5
- Support: 4/5
- Data Management: 3.5/5
- Security: 3.9/5
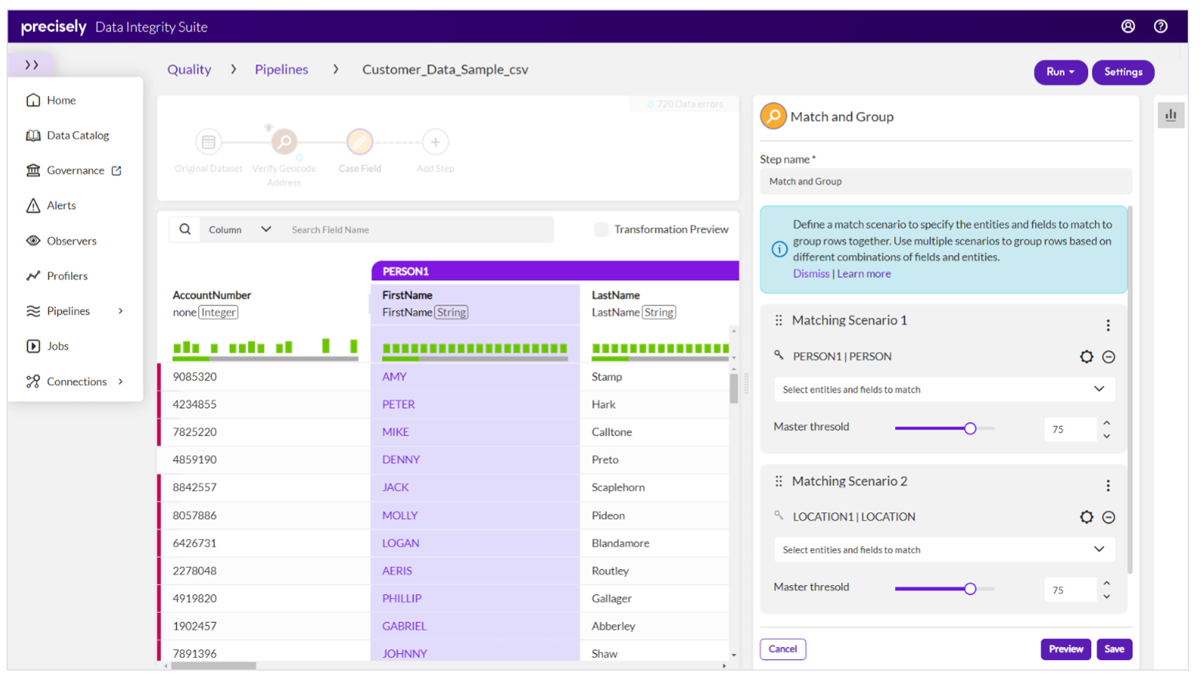
A modular suite of seven interoperable data quality and management tools introduced in 2020, Precisely Data Integrity Suite includes: Data Integration, Data Observability, Data Governance, Data Quality, Geo Addressing, Spatial Analytics, and Data Enrichment. The platform supports all major cloud data warehouses and receives high marks for their responsive customer support.
Visit PreciselyPricing
- Vendor does not provide pricing
- Software costs $500,000 per year on AWS Marketplace
Features
- Automated data anomaly and outlier alerts
- Curated datasets for data enrichment
- Plain language search
| Pros | Cons |
|---|---|
| Near-natural language rule creation | High pricing |
| Responsive phone and online customer support | Underutilized user community |
![]()
SAS Data Quality
Best for collaboration
Overall Rating: 4.2/5
- Cost: 1.25/5
- Core Features: 5/5
- Support: 4.5/5
- Data Management: 5/5
- Security: 5/5
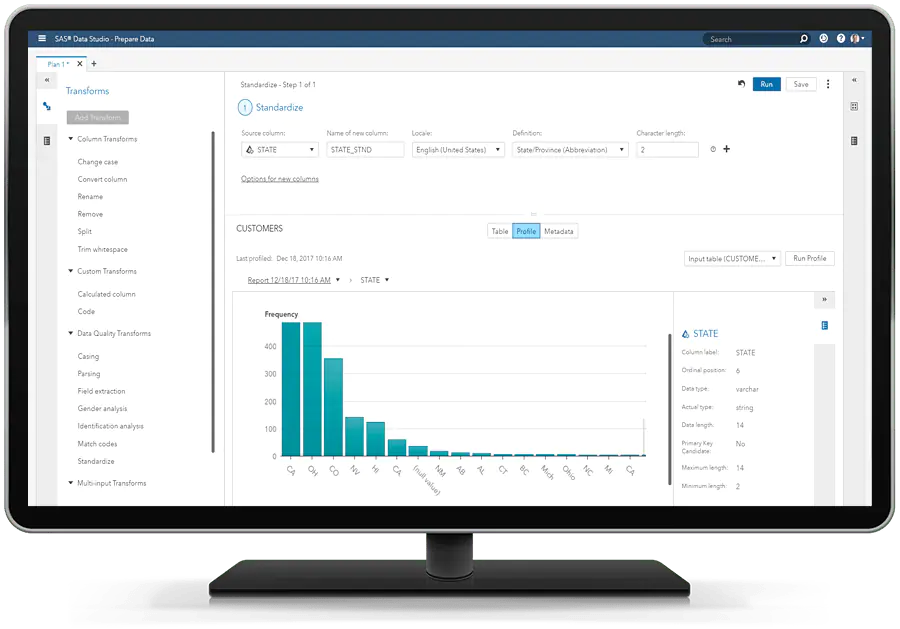
SAS Data Quality offers a user-friendly interface for data cleansing, transformation, and monitoring that allows teams across the business to collaborate on the development of a business glossary and data lineage. Visualization and reporting tools make it easy to monitor and share information about data health.
Visit Sas Data QualityPricing
- Vendor does not provide pricing
- Two-week free trial is available
Features
- Data profiling, standardization, cleansing, and monitoring
- Business glossary, lineage, and metadata management
- Data visualization and reporting
| Pros | Cons |
|---|---|
| Out-of-the-box functionality allows hands-on management by non-technical users | Limited support options and training |
| Charts and graphs facilitate data sharing |
![]()
Talend Data Fabric
Best for understanding your data reliability
Overall Rating: 3.5/5
- Cost: 0.75/5
- Core Features: 4.65/5
- Support: 4/5
- Data Management: 3.5/5
- Security: 4.9/5
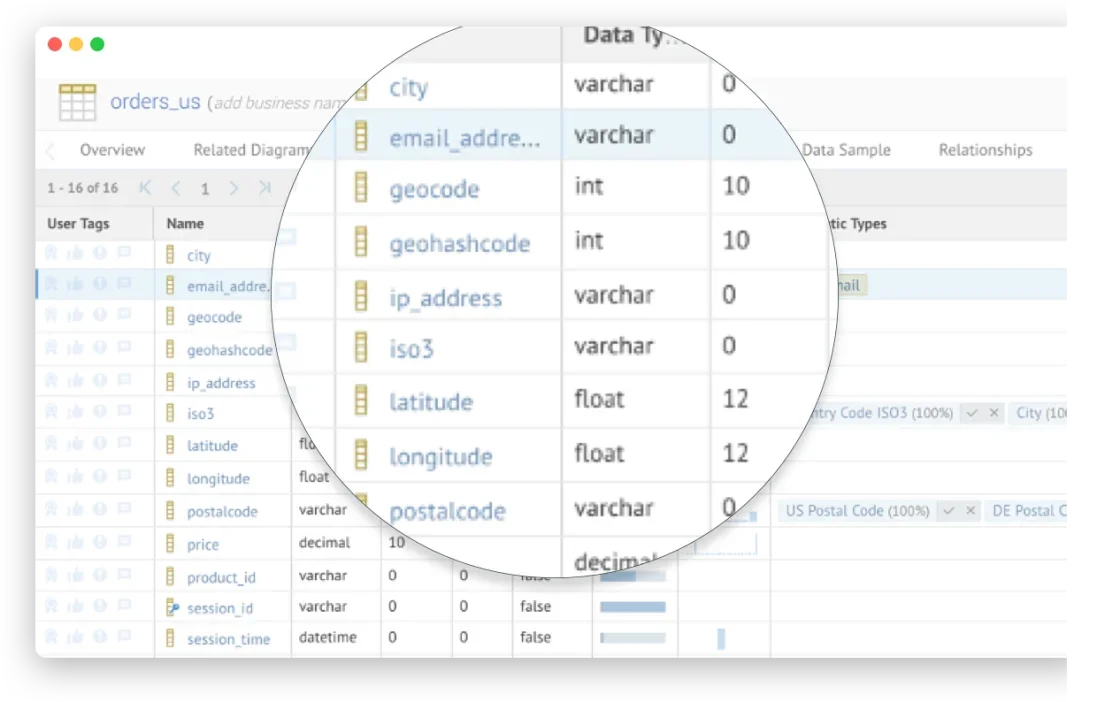
Talend Data Fabric is a platform that brings together the company’s Data Integration, Data Quality, and Data Integrity and Governance tools, along with its Application and API Integration. The tool automatically cleans and profiles data as it enters your systems and assigns trust scores to your data to help you understand its reliability at a glance.
Visit TalendPricing
- Vendor does not provide pricing
- Two-week free trial available
Features
- Data profiling with built-in trust score
- Build reusable data pipelines
- Automated recommendations for addressing data quality issues
| Pros | Cons |
|---|---|
| Built-in data masking to protect sensitive data | Limited introductory training (additional training available with a subscription) |
| Talend Trust Score allows at-a-glance identification of problems |
Key Features of Data Quality Tools
All of the data quality tools included here provide a full range of data cleansing and transformation functions. But data quality tools have begun to evolve with the rise of artificial intelligence and machine learning, which help automate workflows and alerts. In addition, several tools on the market have moved past cleansing and transformation into data management and governance, allowing businesses to continually monitor their data for any issues, trace problems back to the root cause, and take steps to mitigate any errors. Here’s a look at the key features of data quality tools.
Data Profiling
At the heart of data quality tools, data profiling is the function of analyzing the data to determine structure, content, and relationships. This data parsing helps determine what needs to be done to integrate data into your systems.
Data Validation
Data validation applies a set of business rules and criteria to the data to flag any issues that need to be addressed before adding it to your system.
Data Standardization
Data often comes into your systems in a variety of formats and with different column headers and vocabularies. Data standardization is the process that applies a set of uniform attributes to the data so that it can be combined.
Deduplication
In large data sets, there is usually some overlap and duplicate content. The process of deduplication finds matching data, compares the data using rules set up by the business, and either combines the data or removes any duplicate records.
Data Matching and Enrichment
Data matching is the process of comparing different sets of data to determine if there is any commonality or overlap. Data matches can be exact or software can use “fuzzy logic” to determine if there’s a match. Data enrichment is the process of connecting data in the system to additional data held elsewhere to develop a more comprehensive profile or record.
Automation
As data sets get larger and data collection is more frequent, automation is a cost- and labor-saving feature that can free up staff time to work on other projects. One of the most common areas of automation in data quality tools is automated workflows. Another common area is automated alerts, which are triggered when the system detects certain conditions or thresholds.
Error and Anomaly Detection
In order to keep data as high quality as possible, it is important to be notified of any errors or potential anomalies as it is ingested so that steps can be taken to mitigate any problems before they arise.
Data Pipeline Integration
Standalone data quality tools need to be able to bring in and work with data from a variety of sources and in a variety of formats. Tools that have pre-built connectors to common data sources and formats help simplify the process of data ingestion.
Data Management
As the functionality of data quality tools has expanded, they have taken on a variety of data management functions. This includes the ability to catalog the data in your systems, facilitate data governance, monitor data over time and alert users to any issues, trace the lineage of data in the system, analyze the root cause of any problems, and analyze the impact of any problems.
How to Choose the Best Data Quality Tool for Your Business
There is a great deal of diversity in the data quality tool market. All of the platforms included in this roundup excel at core functions, but some are better suited for different applications. Here are a few tips to help you narrow the choices.
- If you need a standalone data quality tool for your business—Consider your budget, the amount of data you need to analyze and transform, the type of data you collect, how much you can and would like to automate your data quality processes, and whether you also need data management and governance functionality.
- If you are limited in budget—Look at tools that specialize in data quality rather than a larger platform or fabric, as specialized tools tend to be lower cost.
- If you work with vast amounts of data—Look for tools that integrate well with large data warehouses and data lakes so that it is easy to set up a pipeline for big data. Certain systems have better ability to work with and transform specific types of data and others have sophisticated automation features.
- If you need a tool that can catalog your data and help with governance and risk management—Look for platforms that combine several different types of tools rather than trying to find separate tools that need to integrate.
Learn about the 10 best enterprise tools for master data management.
How We Evaluated Data Quality Tools
To rate these data quality tools, we considered five key composite criteria: cost, core features, data management features, support, and security. We then analyzed the products using a weighted scoring rubric—our scoring system ranks products from 0 to 5. The best solutions are chosen from that short list. Percentages represent the weight of the total score for each product.
Cost | 20 percent
In evaluating the top seven data quality tools, pricing considerations include the advertised cost, the price of add-ons and options, available pricing tiers, any upgrades or discounts, and whether a free tier and/or trial version is available. If the vendor did not provide pricing for a tool, they did not receive any score in that category.
Core Features | 25 percent
The core features evaluated for each data quality tool included data profiling, data validation, data standardization, deduplication, data matching, data enrichment, automated workflow, automated alerts, rule creation, error detection, and data pipeline integration.
Data Management Features | 25 percent
Since many top data quality tools have expanded to include data management features, we also looked at whether the platform offers a data catalog, data governance, data monitoring, data lineage, root cause analysis, and impact analysis.
Support | 15 percent
The support evaluation included the availability of training and onboarding, phone and online support, a knowledge base, a user community and videos and webinars.
Security | 15 percent
We looked at data access controls, logging and auditing, encryption, how the systems handle data masking, the results of security audits (SOC 2 Type 2, ISO 27001), and whether they facilitate GDPR and CCPA compliance.
Frequently Asked Questions (FAQs)
FAQ #1 What features should businesses look for in data quality tools?
- Data cleansing: ability to profile, validate, standardize, match, deduplicate, and enrich data.
- Ability to create and automate workflows and alerts.
- Connections with a variety of data sources and formats.
- Ability to manage and monitor data over time.
- Responsive customer service.
- Robust security and privacy tools.
FAQ #2 Can data quality tools address data privacy and compliance concerns?
Data privacy and compliance is a critical feature of data quality tools. Look for tools that offer end-to-end encryption of data in transit, that encrypt data at rest, and that make it easy to mask personal identifying information (PII) data. Make sure that the tool creates and allows you to download logs of all user activities so that you can use them for audit purposes. Ask vendors how their platform can help you comply with regional privacy regulations, such as GDPR and CCPA.
FAQ #3 Are there specific industries that can benefit the most from using data quality tools?
Any business can benefit from using data quality tools. If your business collects and wants to use customer data, sales data, operations data, or industry data, it is important to ensure that you have data that is clean, accurate, and complete to help you make business decisions.
Bottom Line: Enterprise Data Quality Tools
Technological advances have allowed businesses to continually collect more data about their customers, prospects, and operations in a diverse array of systems and formats. The challenge for companies is in transforming this data into useful and actionable insights. Evidence-based decision making is only as good as the data that informs the process and small problems with data sources can compound to create faulty insights down the road.
Data quality tools help organizations with a wide range of functions that together help ensure that it is accurate and reliable. If you want to use evidence-based decision-making to grow your business, you need high quality data to inform those decisions—and the right data quality tool to help you clean, validate, and standardize that data is a critical component of your analytics software stack.
Learn about the 7 best data analytics tools for enterprises and how they fit with data quality as part of a larger data management strategy.