Also see: Hadoop and Big Data: 60 Top Open Source Tools
And: 15 Hadoop Vendors Leading the Big Data Market
And: Hadoop and Big Data: Still the Big Dog
Hadoop and Big Data are in many ways the perfect union – or at least they have the potential to be.
Hadoop is hailed as the open source distributed computing platform that harnesses dozens – or thousands – of server nodes to crunch vast stores of data. And Big Data earns massive buzz as the quantitative-qualitative science of harvesting insight from vast stores of data.
You might think of Hadoop as the horse and Big Data as the rider. Or perhaps more accurate: Hadoop as the tool and Big Data as the house being built. Whatever the analogy, these two technologies – both seeing rapid growth – are inextricably linked.
However, Hadoop and Big Data share the same “problem”: both are relatively new, and both are challenged by the rapid churn that’s characteristic of immature, rapidly developing technologies.
Hadoop was developed in 2006, yet it wasn’t until Cloudera’s launch in 2009 that it moved toward commercialization. Even years later it prompts mass disagreement. In June 2015 The New York Times offered the gloomy assessment that Companies Move On From Big Data Technology Hadoop. Furthermore, leading Big Data experts (see below) claim that Hadoop suffers major headwinds.
Similarly, while Big Data has been around for years – called “business intelligence” long before its current buzz – it still creates deep confusion. Businesses are unclear about how to harness its power. The myriad software solutions and possible strategies leaves some users only flummoxed. There’s backlash, too, due to its level of Big Data hype. There’s even confusion about the term itself: “Big Data” has as many definitions as people you’ll ask about it. It’s generally defined as “the process of mining actionable insight from large quantities of data,” yet it also includes machine learning, geospatial analytics and an array of other intelligence uses.
No matter how you define it, though, Big Data is increasingly the tool that sets businesses apart. Those that can reap competitive insights from a Big Data solution gain key advantage; companies unable to leverage this technology will fall behind.
Big bucks are at stake. Research firm IDC forecasts that Big Data technology and services will grow at a 26.4% compound annual growth rate through 2018, to become a $41.4 billion dollar global market. If accurate, that forecast means it’s growing a stunning six times the rate of the overall tech market.
Research by Wikibon predicts a similar growth rate; the chart below reflects Big Data’s exponential growth from just a few years ago. Given Big Data’s explosive trajectory, it’s no wonder that Hadoop – widely seen as a key Big Data tool – is enjoying enormous interest from enterprises of all sizes.
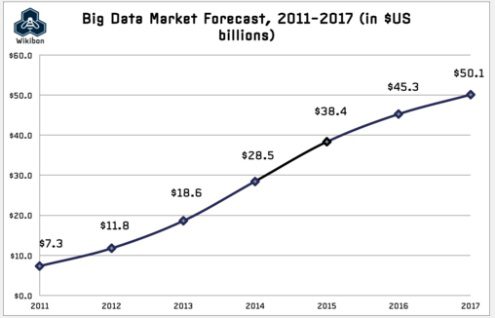
Source: Wikibon
Hadoop and Big Data: The Perfect Union?
Whether Hadoop and Big Data are the ideal match “depends on what you’re doing,” says Nick Heudecker, a Gartner analyst who specializes in Data Management and Integration.
“Hadoop certainly allows you to onboard a tremendous amount of data very quickly, without making any compromises about what you’re storing and what you’re keeping. And that certainly facilitates a lot of the Big Data discovery,” he says.
However, businesses continue to use other Big Data technologies, Heudecker says. A Gartner survey indicates that Hadoop is the third choice for Big Data technology, behind Enterprise Data Warehouse and Cloud Computing.
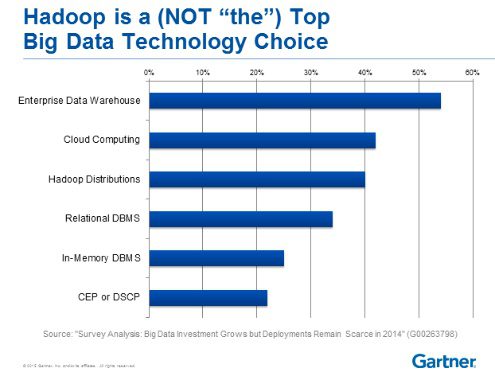
While Hadoop is a leading Big Data tool, it is not the top option for enterprise users.
It’s no surprise that the Enterprise Data Warehouse tops Hadoop as the leading Big Data technology. A company’s complete history and structure can be represented by the data stored in the data warehouse. Moreover, Heudecker says, based on the Gartner user survey, “we see the Enterprise Data Warehouse being combined with a variety of different databases: SQL, graph databases, memory technologies, complex processing, as well as stream processing.”
So while Hadoop is a key Big Data tool, it remains one contender among many at this point. “I think there’s a lot of value in being able to tell a cohesive federated story across multiple data stores,” Huedecker says. That is, “Hadoop being used for some things; your data warehouse being used for others. I don’t think anybody realistically wants to put the whole of their data into a single platform. You need to optimize to handle the potential workloads that you’re doing.”
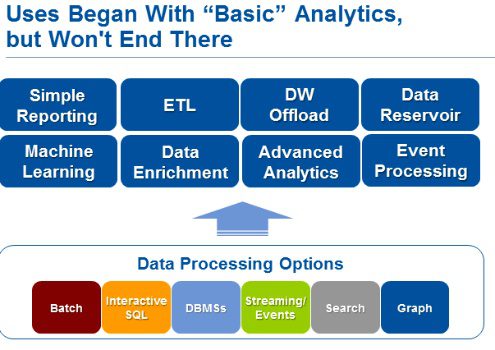
Hadoop offers a full ecosystem along with a single Big Data platform. It is sometimes called a “data operating system.” Source: Gartner
Mike Gualtieri, a Forrester analyst whose key coverage areas include Big Data strategy and Hadoop, notes that Hadoop is part of a larger ecosystem – but it’s a foundational element in that data ecosystem.
“I would say ‘Hadoop and friends’ is a perfect match for Big Data,” Gualtieri says. A variety of tools can be combined for best results. “For example, you need streaming technology to process real-time data. There’s software such as DataTorrent that runs on Hadoop, that can induce streaming. There’s Spark [more on Spark later]. You might want to do batch jobs that are in memory, and it’s very convenient, although not required, to run that Spark cluster on a Hadoop cluster.”
Still, Hadoop’s position in the Big Data universe is truly primary. “I would say Hadoop is a data operating system,” Gualtieri says. “It’s a fundamental, general purpose platform. The capabilities that it has those of an operating system: It has a file system, it has a way to run a job.” And the community of vendors and open source projects all feed into a healthy stream for Hadoop. “They’re making it the Big Data platform.”
In fact, Hadoop’s value for Big Data applications goes beyond its primacy as a data operating system. As Gualtieri sees it, Hadoop is also an application platform. This capability is enabled by YARN, the cluster management technology that’s part of Hadoop (YARN stands for Yet Another Resource Manager.)
“YARN is really an important piece of glue here because it allows innovation to occur in the Big Data community,” he says, “because when a vendor or an open source project contributes something new, some sort of new application, whether it’s machine learning, streaming, a SQL engine, an ETL tool, ultimately, Hadoop becomes an application platform as well as a data platform. And it has the fundamental capability to handle all of these applications, and to control the resources they use.”
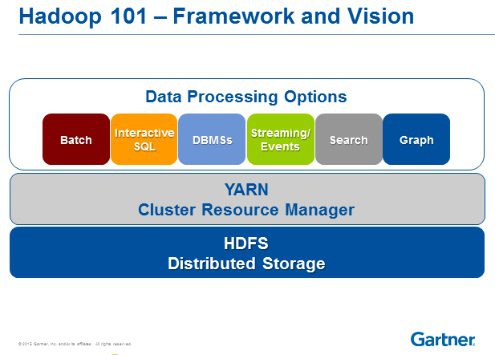
YARN and HDFS provide Hadoop with a diverse array of capabilities.
Regardless of how technology evolves in the years ahead, Hadoop will always have a place in the pioneering days of Big Data infancy. There was a time when many businesses looked at their vast reservoir of data – perhaps a sprawling 20 terabytes – and in essence gave up. They assumed it was too big to be mined for insight.
But Hadoop changed that, notes Mike Matchett, analyst with the Tenaja Group who specializes in Big Data. The development of Hadoop meant “Hey, if you get fifty white node cluster servers – they don’t cost you that much – you get commodity servers, there’s no SAN you have to have because you can use HDFS and local disc, you can do something with it. You can find [Big Data insights]. And that was when [Hadoop] kind of took off.”
Who’s Choosing Hadoop as a Big Data Tool
Based on Gartner research, the industries most strongly drawn to Hadoop are those in banking and financial services. Additional Hadoop early adopters include “more generally, services, which we define as anyone selling software or IT services,” Heudecker says. Insurance, as well as manufacturing and natural resources also see Hadoop users.
Those are the kinds of industries that encounter more – and more diverse – kinds of data. “I think Hadoop certainly lends itself well to that, because now you don’t have to make compromises about what you’re going to keep and what you’re going to store,” Heudecker says. “You just store everything and figure it out later.”
On the other hand, there are laggards, says Teneja Group’s Matchett. “You see people who say, ‘We’re doing fine with our structured data warehouse. There’s not a lot of real-time menus for the marketing we’re doing yet or that we see the need for.’”
But these slow adopters will get on board, he says. “They’ll come around and say, ‘If we have a website and we have any user-tracking and it’s creating a quick stream of Big Data, we’re going to have to use that for market data.’” And really, he asks, “Who doesn’t have a website and a user base of some kind?”
Forrester’s Gualtieri notes that interest in Hadoop is very high. “We did a Hadoop Wave,” he say, referring to the Forrester report Big Data Hadoop Solutions. “We evaluated and published that last year, and of all of the thousands of Forrester documents published that year on all kinds of topics, it was like the second most read document.” Driving this popularity is Hadoop’s fundamental place as a data operating system, he says.
Furthermore, “The amounts of investments by – and I’m not even talking about the startup guys – the investments by companies like SAS, IBM, Microsoft, all of the commercial guys – their goal is to make it easy and do more sophisticated things,” Gaultieri says. “So there’s a lot of value being added.”
He foresees a potential scenario in which Hadoop is part of every operating system. And while adoption is still growing, “I estimate that in the next few years, the next 2-3 years, it will be 100 percent,” of enterprises will deploy Hadoop. Gaultieri refers to a phenomenon he calls “Hadoopenomics,” that is, Hadoop’s ability to unlock a full ecosystem of profitable Big Data scenarios, chiefly because Hadoop offers lower cost storing and accessing of data, relative to a sophisticated data warehouse. “It’s not as capable as a data warehouse, but it’s good for many things,” he says.
Hadoop Headwinds
Yet not all is rosy in the world of Hadoop. Recent Gartner research about Hadoop adoption notes that “investment remains tentative in the face of sizable challenges around business value and skills.”
The May 2015 report, co-authored by Heudecker and Gartner analyst Merv Adrian, states:
“Despite considerable hype and reported successes for early adopters, 54 percent of survey respondents report no plans to invest at this time, while only 18 percent have plans to invest in Hadoop over the next two years. Furthermore, the early adopters don’t appear to be championing for substantial Hadoop adoption over the next 24 months; in fact, there are fewer who plan to begin in the next two years than already have.”
“Only 26 percent of respondents claim to be either deploying, piloting or experimenting with Hadoop, while 11 percent plan to invest within 12 months and seven percent are planning investment in 24 months. Responses pointed to two interesting reasons for the lack of intent. First, several responded that Hadoop was simply not a priority. The second was that Hadoop was overkill for the problems the business faced, implying the opportunity costs of implementing Hadoop were too high relative to the expected benefit.”
The Gartner report’s gloomiest news for Hadoop:
With such large incidence of organizations with no plans or already on their Hadoop journey, future demand for Hadoop looks fairly anemic over at least the next 24 months. Moreover, the lack of near-term plans for Hadoop adoption suggest that, despite continuing enthusiasm for the big data phenomenon, demand for Hadoop specifically is not accelerating. The best hope for revenue growth for providers would appear to be in moving to larger deployments within their existing customer base.”
I asked Heudecker about these Hadoop impediments and he noted the lack of IT pros with top Hadoop skills:
“We talked with a large financial services organization, they were just starting their Hadoop journey,” he says, “and we asked, ‘Who helped you?’ And they said ‘Nobody, because the companies we called had just as much experience with Hadoop as we did.’ So when the largest financial service companies on the planet can’t find help for their Hadoop project, what does that mean for the global 30,000 companies out there?”
This lack of skilled tech pros for Hadoop is a true concern, Heudecker says. “That’s certainly being borne out in the data that we have, and in the conversations that we have with clients,” he says. “And I think it’s going to be a while before Hadoop skills are plentiful in the market.”
Gualtieri, however, voices quite a different view. The idea that Hadoop faces a lack is skilled workers is “a myth” he says. Hadoop is based on Java, he notes. “A large enterprise has lots of Java developers, and Java developers over the years always have to learn new frameworks. And guess what? Just take a couple of your good Java guys and say, ‘Do this on Hadoop,’ and they will figure it out. It’s not that hard.” Java developers will be able to get a sample app running that can do simple tasks before long, he says.
These in-house, homegrown Hadoop experts enable cost savings, he says. “So instead of looking for the high-priced Hadoop experts who say, ‘I know Hadoop,’ what I see when I talk to a lot of enterprises, I’m talking to people who have been there for ten years – they just became the Hadoop expert.”
An additional factor makes Hadoop dead simple to adopt, Gualtieri says: “That is SQL for Hadoop. SQL is known by developers. It’s known by many business intelligence professionals, and even business people and data analysis [professionals], right? It’s very popular.
“And there are at least thirteen different SQL for Hadoop query engines on Hadoop. So you don’t need to know a thing about MapReduce. You don’t need to know anything about distributed data or distributed jobs” to accomplish an effective query.
Gualtieri points to a diverse handful of Hadoop SQL solutions: “Apache Drill, Cloudera Impala, Apache Hive …Presto, HP Vertica has a solution, Pivotal Hawk, Microsoft Polybase… Naturally all the database companies and data warehouse companies have a solution. They’ve repurposed their engines. And then there the open source firms.” All (or most) of these solutions tout their usability.
Matchett takes a middle ground between Heudecker’s view that Hadoop faces a shortage of skilled workers and Gualtieri’s belief that in-house Java developers and vendor solutions can fill the gap:
“There are plenty of places where people can get lots of mileage out of it,” he says, referring to easy-to-use Hadoop deployments – particularly AWS’s offering. “You and I can both go to Amazon with a credit card and check out an EMR cluster, which is a Hadoop cluster, and get it up and running without knowing anything. You could do that in ten minutes with your Amazon account and have a Big Data cluster.”
However, “at some level of professionalism or scale of productivity, you’re going to need experts, still,” Matchett says. “Just like you would with an RDBMS. It’s going to be pretty much analogous to that.” Naturally these experts are more expensive and harder to find.
To be sure, there are easier solutions: “There are lots of startup businesses that are committed to being cloud-based and Web-based, and there’s no way they’re going to go run their Hadoop clusters internally,” Matchett says. “They’re going to check them out of the cloud.”
Again, though, at some point they may need top talent: “They may still want a data scientist to solve their unique competitive problem. They need the scientist to figure out what they can do differently than their competitors or anybody else.”
The Hadoop/Big Data Vendor Connection
A growing community of Hadoop vendors offer a byzantine array of solutions. Flavors and configurations abound. These vendors are leveraging the fact that Hadoop has a certain innate complexity – meaning buyers need some help. Hadoop is comprised of various software components, all of which need to work in concert. Adding potential confusion, different aspects of the ecosystem progress at varying speeds.
Handling these challenges is “one of the advantages of working with a vendor,” Heudecker says. “They do that work for you.” As mentioned, a key element of these solutions is SQL – Heudecker refers to SQL as “the Lingua Franca of data management.”
Is there a particular SQL solution that will be the perfect match for Hadoop?
“I think over the next 3-5 years, you’ll actually see not one SQL solution emerge as a winner, but you’ll likely see several, depending on what you want to do,” Heudecker says. “In some cases Hive may be your choice depending on certain use cases. In other cases you may want to use Drill or something like Presto, depending on what your tools will support and what you want to accomplish.”
As for winner or losers in the race for market share? “I think it’s too soon. We’ll be talking about survivors, not winners.”
The emerging community of vendors tends to tout one key attribute: ease of use. Matchett notes that, “If you go to industry events, it’s just chock full of startups saying, ‘Hey, we’ve got this new interface that allows the business [user] just to drag and drop and leverage Big Data without having to know anything.’”
He compares the rapid evolution in Hadoop tools to the evolution of virtualization several years ago. If a vendor wants to make a sale, simpler user interface is a selling point. Hadoop vendors are hawking their wares by claiming, “‘We’ve got it functional. And now we’re making it manageable,’” Matchett says. “‘We’re making it mature and we’re adding security and remote-based access, and we’re adding availability, and we’re adding ways for DevOps people to control it without having to know a whole lot.’”
Hadoop Appliances: Big Data in a Box
Even as Hadoop matures, there continues to be Big Data solutions that far outmatch it – at a higher price for those who need greater capability.
“There’s still definitely a gap between what a Teradata warehouse can do, or an IBM Netezza, Oracle Exadata, and Hadoop,” says Forrester’s Gualtieri. “I mean, if you need high concurrency, if you need tons of users and you’re doing really complicated queries that you need to have perform super fast, that’s just like if you’re in a race and you need race car.” In that case you simply need the best. “So, there’s still a performance gap, and there’s a lot of engineering work that has to be done.”
One development that he finds encouraging for Hadoop’s growth is the rise of the Hadoop appliance. “Oracle has the appliance, Teradata has the appliance, HP is coming out with an appliance based upon their Moonshot, [there’s] Cray Computer, and others,” he notes, adding Cisco to his list.
What’s happening now is far beyond what might be called “appliance 1.0 for Hadoop,” Gualtieri says. That first iteration was simply a matter of getting a cabinet, putting some nodes in it, installing Hadoop and offering it to clients. “But what they’re doing now is they’re saying, okay, ‘Hadoop looks like it’s here to stay. How can we create an engineered solution that helps overcome some of the natural bottlenecks of Hadoop? That helps IO throughput, uses more caching, puts computer resources where they’re needed virtually?’ So, now they’re creating a more engineered system.”
Matchett, too, notes that there’s renewed interest in Hadoop appliances after the first wave. “DDN, a couple years ago, had an HScaler appliance where they packaged up their super-duper storage and compute modes and sold it as a rack, and you could buy this Hadoop appliance.”
Appliances appeal to businesses. Customers like being able to download Hadoop for free, but when it comes to turning it into a workhorse, that task (as noted above) calls for expertise. It’s often easier to simply buy a pre-built appliance. Companies “don’t want to go hire an expert and waste six months converging it themselves,” Matchett says. “So, they can just readily buy an appliance where it’s all pre-baked, like a VCE appliance such VBlock, or a hyper-converged version that some other folks are considering selling. So, you buy a rack of stuff…and it’s already running Hadoop, Spark, and so on.” In short, less headaches, more productivity.
Big Data Debate: Hadoop vs. Spark, or Hadoop and Spark?
A discussion – or debate – is now raging within the Big Data community: sure, Hadoop is hot, but now Spark is emerging. Maybe Spark is better – some tech observers trumpet its advantages – and so Hadoop (some observers suggest) will soon fade from its high position.
Like Hadoop, Spark is a cluster computing platform (both Hadoop and Spark are Apache projects). Spark is earning a reputation as a good choice for complicated data processing jobs that need to be performed quickly. Its in-memory architecture and directed acyclic graph (DAG) processing is far faster than Hadoop’s MapReduce – at least at the moment. Yet Spark has its downsides. For instance, it does not have its own file system. In general, IT pros think of Hadoop is best for volume where Spark is best for speed, but in reality the picture isn’t that clear.

Spark’s proponents point out that processing is far faster when the data set fits in memory.
“I think there’s an awful lot of hype out there,” Gualtieri says. To be sure, he thinks highly of Spark and its capabilities. And yet: “There are some things it doesn’t do very well. Spark, for example, doesn’t have its own file system. So it’s like a car without wheels.”
The debate doesn’t take into consideration how either Spark or Hadoop might evolve – quickly. For instance, Gualtieri says, “Some people will say Hadoop’s much slower than Spark because it’s disc-based. Does it have to be disc-based six months from now? In fact, part of the Hadoop community is working on supporting SSD cards, and then later, files and memory. So people need to understand that, especially now with this Spark versus Hadoop fight.”
The two processing engines are often compared. “Now, most Hadoop people will say MapReduce is lame compared to the [Spark] DAG engine,” Gualtieri says. “The DAG engine is superior to MapReduce because it helps the programmer parallelize jobs much better. But who’s to say that someone couldn’t write a DAG engine for Hadoop? They could. So, that’s what I’m saying: This is not a static world where code bases are frozen. And this is what annoys me about the conversations, is that it’s as if these technologies are frozen in time and they’re not going to evolve and get better.” But of course they are – and likely sooner rather than later.

Like Hadoop, Spark includes an ever growing array of tools and features to augment the core platform. Source: Forrester Research
Ultimately the Hadoop-Spark debate may not matter, Matchett says, because the two technologies may essentially merge, in some form. In any case, “What you’re still going to have is a commodity Big Data ecosystem, and whether the Spark project wins, or the Map Reduce project wins, Spark is part of Apache now. It’s all part of that system.”
As Hadoop and Spark evolve, “They could merge. They could marry. They could veer off in different directions. I think what’s important, though, is that you can run Hadoop and Spark jobs in the same cluster.”
Plenty of options confront a company seeking to assemble a Big Data toolset, Matchett points out. “If you were to white board it and say ‘I’ve got this problem I want to solve, do I use Map Reduce? Do I use Spark? Do I use one of the other dozen things that are out there? Or a SQL database or a graph database?’ That’s a wide open discussion about architecture.” Ultimately there are few completely right and wrong answers, only a question of which solution(s) work best for a specific scenario.
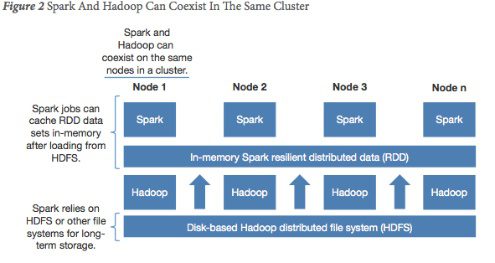
Instead of a choosing one or the other, many Big Data practitioners point to a scenario in which Hadoop and Spark work in tandem to enable the best of both.
Hadoop and Big Data Future Speak: Data Gravity, Containers, IoT
Clearly, there’s been a lot of hype about Big Data, about how it’s the new Holy Grail of business decision making.
That hype may have run its course. “Big data is essentially turning into data,” opines Heudecker. “It’s time to get past the hype and start thinking about where the value is for your business.” The point: “Don’t treat Big Data as an end unto itself. It has to derive from a business need.”
As for Hadoop’s role in this, its very success may contain a paradox. With time, Hadoop may grow less visible. It may become so omnipresent that it’s no longer seen as a stand alone tool.
“Over time, Hadoop will eventually bake into your information infrastructure,” Huedecker says. “It should never have been an either/or choice. And it won’t be in the future. It will be that I have multiple data stores. I will use them depending on the SLAs I have to comply with for the business. And so you’ll have a variety of different data stores.”
In Gualtieri’s view, the near term future of Hadoop is based on SQL. “What I would say this year is that SQL on Hadoop is the killer app for Hadoop,” he says. “It’s going to be the application on Hadoop that allows companies to adopt Hadoop very easily.” He predicts: “In two years from now you’re going to see companies building applications specifically that run on Hadoop.”
Looking ahead, Gualtieri sees the massive Big Data potential of the Internet of Things as a boost for Hadoop. For instance, he points to the ocean of data created by cable TV boxes. All that data needs to be stored somewhere.
“You’re probably going to want to dump that in the most economical place possible, which is HDFS [in Hadoop],” he says, “and then you’re probably going to want to analyze it to see if you can predict who’s watching the television at that time, and predict the volumes [of user trends], and you’ll probably do that in the Hadoop cluster. You might do it in Spark, too. You might take a subset to Spark.”
He adds, “A lot of the data that’s landed in Hadoop has been very much about moving data from data warehouses and transactional systems into Hadoop. It’s a more central location. But I think for companies where IOT is important, that’s going to create even more of a need for a Big Data platform.”
As an aside, Gualtieri made a key point about Hadoop and the cloud, pointing to what he calls “the myth of data gravity.” Businesses often ask him where to store their data: in the cloud? on premise? The conventional wisdom is that you should store your data where you handle most of your analytics and processing. However, Gualtieri disagrees – this attitude is too limiting, he says.
Here’s why data gravity is a myth: “It probably takes only about 50 minutes to move a terabyte to the cloud, and a lot of enterprises only have a hundred terabytes.” So if your Hadoop cluster resides in the cloud, it would take mere hours to move your existing data to the cloud, after which it’s just incremental updates. “I’m hoping companies will understand this, so that some of them can actually use the cloud, as well,” he says.
When Matchett looks to the future of Hadoop and Big Data, he sees the affect of convergence: any number of vendors and solutions combining together to handle an ever more flexible array of challenges. “We’re just starting to see a little bit [of convergence] where you have platforms, scale-up commodity platforms with data processing, that have increasing capabilities,” he says. He points to the combination of MapReduce and Spark. “We also have those SQL databases that can run on these. And we see databases like Vertica coming in to run on databases with the same platforms…Green Plum from EMC, and some from Teradata.”
He adds: “If you think about that kind of push, the data lake makes more sense not as a lake of data, but as a data processing platform where I can do anything I want with the data I put there.”
The future of Hadoop and Big Data will contain a multitude of technologies all mixed and matched together – including today’s emerging container technology.
“You start to look at what’s happening, with workload scheduling and container scheduling and container cluster management, and there’s Big Data from this side coming in and you realize: well, what MapReduce is, it’s really a Java job that gets mapped out. And what a container really is, it’s a container that holds a Java application… You start to say, we’re really going to see a new kind of data center computing architecture take hold, and it started with Hadoop.”
How will it all evolve? As Matchett notes, “the story is still being written.”
Front page graphic courtesy of Shutterstock.
-
Huawei’s AI Update: Things Are Moving Faster Than We Think
FEATURE | By Rob Enderle,
December 04, 2020
-
Keeping Machine Learning Algorithms Honest in the ‘Ethics-First’ Era
ARTIFICIAL INTELLIGENCE | By Guest Author,
November 18, 2020
-
Key Trends in Chatbots and RPA
FEATURE | By Guest Author,
November 10, 2020
-
Top 10 AIOps Companies
FEATURE | By Samuel Greengard,
November 05, 2020
-
What is Text Analysis?
ARTIFICIAL INTELLIGENCE | By Guest Author,
November 02, 2020
-
How Intel’s Work With Autonomous Cars Could Redefine General Purpose AI
ARTIFICIAL INTELLIGENCE | By Rob Enderle,
October 29, 2020
-
Dell Technologies World: Weaving Together Human And Machine Interaction For AI And Robotics
ARTIFICIAL INTELLIGENCE | By Rob Enderle,
October 23, 2020
-
The Super Moderator, or How IBM Project Debater Could Save Social Media
FEATURE | By Rob Enderle,
October 16, 2020
-
Top 10 Chatbot Platforms
FEATURE | By Cynthia Harvey,
October 07, 2020
-
Finding a Career Path in AI
ARTIFICIAL INTELLIGENCE | By Guest Author,
October 05, 2020
-
CIOs Discuss the Promise of AI and Data Science
FEATURE | By Guest Author,
September 25, 2020
-
Microsoft Is Building An AI Product That Could Predict The Future
FEATURE | By Rob Enderle,
September 25, 2020
-
Top 10 Machine Learning Companies 2020
FEATURE | By Cynthia Harvey,
September 22, 2020
-
NVIDIA and ARM: Massively Changing The AI Landscape
ARTIFICIAL INTELLIGENCE | By Rob Enderle,
September 18, 2020
-
Continuous Intelligence: Expert Discussion [Video and Podcast]
ARTIFICIAL INTELLIGENCE | By James Maguire,
September 14, 2020
-
Artificial Intelligence: Governance and Ethics [Video]
ARTIFICIAL INTELLIGENCE | By James Maguire,
September 13, 2020
-
IBM Watson At The US Open: Showcasing The Power Of A Mature Enterprise-Class AI
FEATURE | By Rob Enderle,
September 11, 2020
-
Artificial Intelligence: Perception vs. Reality
FEATURE | By James Maguire,
September 09, 2020
-
Anticipating The Coming Wave Of AI Enhanced PCs
FEATURE | By Rob Enderle,
September 05, 2020
-
The Critical Nature Of IBM’s NLP (Natural Language Processing) Effort
ARTIFICIAL INTELLIGENCE | By Rob Enderle,
August 14, 2020
SEE ALL
DATA CENTER ARTICLES

