

The following excerpt is from Big Data For Dummies, published 2013 by Wiley.
Also see: Three of the authors, Judith Hurwitz, Fern Halper and Marcia Kaufman, discussed Big Data in a recent Google Hangout, Finding the Small in Big Data.
Like any important data architecture, you should design a model that takes a holistic look at how all the elements need to come together. Although this will take some time in the beginning, it will save many hours of development and lots of frustration during the subsequent implementations. You need to think about big data as a strategy, not a project.
Good design principles are critical when creating (or evolving) an environment to support big data — whether dealing with storage, analytics, reporting, or applications. The environment must include considerations for hardware, infrastructure software, operational software, management software, well-defined application programming interfaces (APIs), and even software developer tools. Your architecture will have to be able to address all the foundational requirements that we discuss in Chapter 1:
✓ Capture
✓ Integrate
✓ Organize
✓ Analyze
✓ Act
Figure 4-1 presents the layered reference architecture we introduce in Chapter 1. It can be used as a framework for how to think about big data technologies that can address functional requirements for your big data projects.
This is a comprehensive stack, and you may focus on certain aspects initially based on the specific problem you are addressing. However, it is important to understand the entire stack so that you are prepared for the future. You’ll no doubt use different elements of the stack depending on the problem you’re addressing.
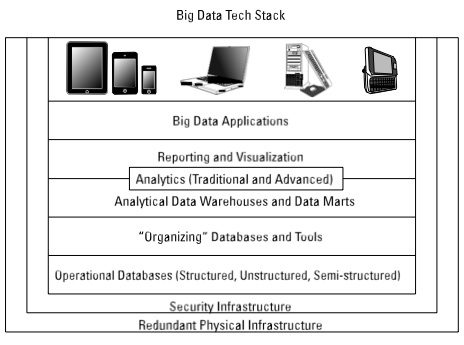
figure 4-1
Chapter 4: Digging into Big Data Technology Components
Layer 0: Redundant Physical Infrastructure
At the lowest level of the stack is the physical infrastructure — the hardware, network, and so on. Your company might already have a data center or made investments in physical infrastructures, so you’re going to want to find a way to use the existing assets. Big data implementations have very specific requirements on all elements in the reference architecture, so you need to examine these requirements on a layer-by-layer basis to ensure that your implementation will perform and scale according to the demands of your business. As you start to think about your big data implementation, it is important to have some overarching principles that you can apply to the approach. A prioritized list of these principles should include statements about the following:
✓ Performance: How responsive do you need the system to be?
Performance, also called latency, is often measured end to end, based on
a single transaction or query request. Very fast (high-performance, low- latency) infrastructures tend to be very expensive.
✓ Availability: Do you need a 100 percent uptime guarantee of service?
How long can your business wait in the case of a service interruption or
failure? Highly available infrastructures are also very expensive.
✓ Scalability: How big does your infrastructure need to be? How much
disk space is needed today and in the future? How much computing
power do you need? Typically, you need to decide what you need and then add a little more scale for unexpected challenges.
✓ Flexibility: How quickly can you add more resources to the infrastruc- ture? How quickly can your infrastructure recover from failures? The most flexible infrastructures can be costly, but you can control the costs with cloud services, where you only pay for what you actually use (see Chapter 6 for more on cloud computing).
✓ Cost: What can you afford? Because the infrastructure is a set of com- ponents, you might be able to buy the “best” networking and decide to save money on storage (or vice versa). You need to establish requirements for each of these areas in the context of an overall budget and then make trade-offs where necessary.
As big data is all about high-velocity, high-volume, and high-data variety, the physical infrastructure will literally “make or break” the implementation. Most big data implementations need to be highly available, so the net- works, servers, and physical storage must be both resilient and redundant. Resiliency and redundancy are interrelated. An infrastructure, or a system, is resilient to failure or changes when sufficient redundant resources are in place, ready to jump into action. In essence, there are always reasons why even the most sophisticated and resilient network could fail, such as a hard- ware malfunction. Therefore, redundancy ensures that such a malfunction won’t cause an outage.
Resiliency helps to eliminate single points of failure in your infrastructure. For example, if only one network connection exists between your business and the Internet, no network redundancy exists, and the infrastructure is not resilient with respect to a network outage. In large data centers with business continuity requirements, most of the redundancy is in place and can be lever- aged to create a big data environment. In new implementations, the designers have the responsibility to map the deployment to the needs of the business based on costs and performance.
As more vendors provide cloud-based platform offerings, the design responsibility for the hardware infrastructure often falls to those service providers.
This means that the technical and operational complexity is masked behind a collection of services, each with specific terms for performance, availability, recovery, and so on. These terms are described in service-level agreements (SLAs) and are usually negotiated between the service provider and the customer, with penalties for noncompliance.
For example, if you contract with a managed service provider, you are theoretically absolved from the worry associated with the specifics of the physical environment and the core components of the data center. The networks, servers, operating systems, virtualization fabric, requisite management tools, and day-to-day operations are inclusive in your service agreements. In effect, this creates a virtual data center. Even with this approach, you should still know what is needed to build and run a big data deployment so that you can make the most appropriate selections from the available service offerings. Despite having an SLA, your organization still has the ultimate responsibility for performance.
Physical redundant networks
Networks should be redundant and must have enough capacity to accommodate the anticipated volume and velocity of the inbound and outbound data in addition to the “normal” network traffic experienced by the business. As you begin making big data an integral part of your computing strategy, it is reasonable to expect volume and velocity to increase.
Infrastructure designers should plan for these expected increases and try to create physical implementations that are “elastic.” As network traffic ebbs and flows, so too does the set of physical assets associated with the implementation. Your infrastructure should offer monitoring capabilities so that operators can react when more resources are required to address changes in workloads.
Managing hardware: Storage and servers
Likewise, the hardware (storage and server) assets must have sufficient speed and capacity to handle all expected big data capabilities. It’s of little use to have a high-speed network with slow servers because the servers will
most likely become a bottleneck. However, a very fast set of storage and compute servers can overcome variable network performance. Of course, nothing will work properly if network performance is poor or unreliable.
Infrastructure operations
Another important design consideration is infrastructure operations manage- ment. The greatest levels of performance and flexibility will be present only
in a well-managed environment. Data center managers need to be able to anticipate and prevent catastrophic failures so that the integrity of the data,
Part II: Technology Foundations for Big Data
and by extension the business processes, is maintained. IT organizations often overlook and therefore underinvest in this area. We talk more about what’s involved with operationalizing big data in Chapter 17.
Layer 1: Security Infrastructure
Security and privacy requirements for big data are similar to the require- ments for conventional data environments. The security requirements have to be closely aligned to specific business needs. Some unique challenges arise when big data becomes part of the strategy, which we briefly describe in this list:
✓ Data access: User access to raw or computed big data has about the same level of technical requirements as non-big data implementations. The data should be available only to those who have a legitimate busi- ness need for examining or interacting with it. Most core data storage platforms have rigorous security schemes and are often augmented with a federated identity capability, providing appropriate access across the
many layers of the architecture.
✓ Application access: Application access to data is also relatively straight- forward from a technical perspective. Most application programming interfaces (APIs) offer protection from unauthorized usage or access. This level of protection is probably adequate for most big data implementations.
✓ Data encryption: Data encryption is the most challenging aspect of security in a big data environment. In traditional environments, encrypt- ing and decrypting data really stresses the systems’ resources. With
the volume, velocity, and varieties associated with big data, this problem is exacerbated. The simplest (brute-force) approach is to provide more and faster computational capability. However, this comes with a steep price tag — especially when you have to accommodate resiliency requirements. A more temperate approach is to identify the data elements requiring this level of security and to encrypt only the necessary items.
✓ Threat detection: The inclusion of mobile devices and social networks exponentially increases both the amount of data and the opportunities for security threats. It is therefore important that organizations take a multiperimeter approach to security.
We talk more about big data security and governance in Chapter 19. We also discuss how big data is being used to help detect threats and other security issues.
Excerpted with permission from the publisher, Wiley, from Big Data For Dummies by Judith Hurwitz, Alan Nugent, Fern Halper and Marcia Kaufman. Copyright (c) 2013.
RELATED NEWS AND ANALYSIS
-
Huawei’s AI Update: Things Are Moving Faster Than We Think
FEATURE | By Rob Enderle,
December 04, 2020 -
Keeping Machine Learning Algorithms Honest in the ‘Ethics-First’ Era
ARTIFICIAL INTELLIGENCE | By Guest Author,
November 18, 2020 -
Key Trends in Chatbots and RPA
FEATURE | By Guest Author,
November 10, 2020 -
FEATURE | By Samuel Greengard,
November 05, 2020 -
ARTIFICIAL INTELLIGENCE | By Guest Author,
November 02, 2020 -
How Intel’s Work With Autonomous Cars Could Redefine General Purpose AI
ARTIFICIAL INTELLIGENCE | By Rob Enderle,
October 29, 2020 -
Dell Technologies World: Weaving Together Human And Machine Interaction For AI And Robotics
ARTIFICIAL INTELLIGENCE | By Rob Enderle,
October 23, 2020 -
The Super Moderator, or How IBM Project Debater Could Save Social Media
FEATURE | By Rob Enderle,
October 16, 2020 -
FEATURE | By Cynthia Harvey,
October 07, 2020 -
ARTIFICIAL INTELLIGENCE | By Guest Author,
October 05, 2020 -
CIOs Discuss the Promise of AI and Data Science
FEATURE | By Guest Author,
September 25, 2020 -
Microsoft Is Building An AI Product That Could Predict The Future
FEATURE | By Rob Enderle,
September 25, 2020 -
Top 10 Machine Learning Companies 2020
FEATURE | By Cynthia Harvey,
September 22, 2020 -
NVIDIA and ARM: Massively Changing The AI Landscape
ARTIFICIAL INTELLIGENCE | By Rob Enderle,
September 18, 2020 -
Continuous Intelligence: Expert Discussion [Video and Podcast]
ARTIFICIAL INTELLIGENCE | By James Maguire,
September 14, 2020 -
Artificial Intelligence: Governance and Ethics [Video]
ARTIFICIAL INTELLIGENCE | By James Maguire,
September 13, 2020 -
IBM Watson At The US Open: Showcasing The Power Of A Mature Enterprise-Class AI
FEATURE | By Rob Enderle,
September 11, 2020 -
Artificial Intelligence: Perception vs. Reality
FEATURE | By James Maguire,
September 09, 2020 -
Anticipating The Coming Wave Of AI Enhanced PCs
FEATURE | By Rob Enderle,
September 05, 2020 -
The Critical Nature Of IBM’s NLP (Natural Language Processing) Effort
ARTIFICIAL INTELLIGENCE | By Rob Enderle,
August 14, 2020
DATA CENTER ARTICLES