

This is the fourth article in a series from Accenture Applied Intelligence on Data Science Transformation. It focuses on unlocking the value of data. The previous article in this series is Data Science: Integrate It.
A company’s ability to unlock the value of data is crucial for sustaining or increasing a competitive edge. The key to success lies in how organizations manage their data transformation journey. Despite having invested millions of dollars, many organizations feel they haven’t made meaningful progress. What’s worse, some believe these investments have only added to the burgeoning legacy cost burden.
The reality: Chronic POCers and Legacy Mourners
To understand these concerns, let’s examine two profiles (figure 1) of companies struggling to unlock value from data:
1. “Chronic POCers”: Typically in the early phases of their journey, companies feel stuck in technology-led experimentation/ proof-of-concept (POC) mode with an inability to scale and monetize high value business use cases. These companies, we believe, struggle to unlock the initial business value of dat
2. “Legacy Mourners”: Organizations that have scaled the first hurdle quickly realize that initial benefits do not sufficiently offset legacy costs and, what’s worse, seem to incrementally add to baseline expenses. These companies struggle to unlock the true enterprise value of data.

The Fix:
Depending on which of these profiles a company is emulating, the solution follows one of two broad themes:
1. Unlocking Business Value of Data: Targeting the Chronic POCers, this solution focuses on enabling new discoveries and quickly and efficiently operationalizing new insights. Key components include:
· Designed-for-purpose data assets: Analytic data sets must be designed for flexibility and usefulness within a specific context. Let the use case drive the transformation.
· Prioritizing and capturing impact from use cases: The real business value of these “big data” sources is always unlocked through specific use cases and applications.
· Hyper focus on data management: A data lake will turn into a data swamp overnight if management, governance and a security framework are not implemented.
· Faster POC time-to-market: Leaders in the industry are using agile and quick-fail POCs with clearly defined exit criteria to demonstrate business value before full scale implementation.
2. Unlocking Enterprise Value of Data: Targeting the Legacy Mourners, this solution focuses on driving scalability, performance, efficiency and risk management as the next major step towards realizing enterprise value. Some of the key components include:
· Redirecting legacy funding to new use cases: Pursue legacy decommissioning and architecture simplification to drive down maintenance costs and to support new big data investments.
· Optimizing backend infrastructure: Consider capability-specific cloud environments, virtualization and query optimization, network optimization, self-optimizing backend infrastructure, etc. as means to drive enhanced performance.
· Leading edge data management: Enable holistic and actionable anomaly detection; AI-driven, dynamic user access controls; a single, comprehensive view into the business and technical metadata, etc. to drive better control.
Additionally, organizations should consider establishing the following in order to successfully unlock value from data:
· Single point of access. Providing a single source, frequently known as a data lake, for broad and diverse sets of data (e.g. transactional, social, IoT).
· “No regret” data layer. Traditional data warehousing focused on bringing only the necessary data in to save money and improve performance. With today’s low cost of data storage, all the data can be landed, and stored, as-is. There is never a need to go back to the source system when requirements change, and there is no risk to losing historical data that may be needed in the future.
· Data stored in its raw format. Just as transactional data models inhibit efficient reporting, reporting data models inhibit analytics. Data scientists spend significant amounts of time transforming data that is optimized for reporting into structures that support analytics. Storing data in its raw format, i.e. reducing transformations, prevents the redundant transformation of data by transforming it once, after the data scientist determines what is needed, and how it is needed.
· Designed-for-purpose data assets. Today’s leaders are curating data sets very differently. Traditionally in the data warehouse we have focused on data modeling for integrity and consistency, which are still important and relevant, but analytic data sets need to be designed for flexibility and usefulness within a specific context. Let the use case drive the transformation. Expecting to generate game changing outcomes with data that is structured to answer descriptive and diagnostic questions is a handicap for your data scientists.
· Analytics sandbox with full masked data sets. IT departments need to let go of the traditional guideline that replicating data is bad. Data scientists need access to full replicas of transactional data, not sample data sets. They need the ability to ‘play’ with the data so it is important that they are using replicated data in a sandbox environment. Replicating the data also allows for important transformations such as masking and anonymizing personally identifiable data.
Accelerating Value Realization
Most companies we have observed start by scaling up big data use cases and then, as they see value being constrained by legacy, consider legacy and platform optimization opportunities. We believe there is a faster and more efficient way to unlock value from data. Converging business value and enterprise value initiatives leads to faster break even and greater ROI. In fact, combining these two initiatives from the start reduces break even timelines by around 30%, while drastically improving overall value realization by around 20% when compared to traditional methods (Refer Figure 2, Chart B).
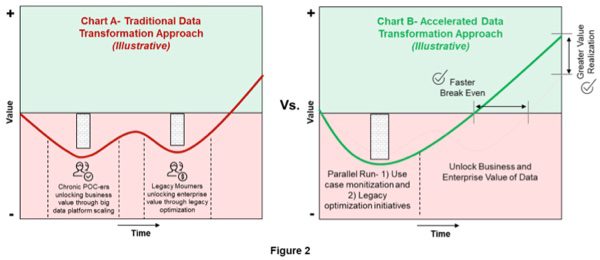
Following the steps above, a large US-based retail and commercial bank seized the opportunity to leapfrog others on the data transformation journey. By combining legacy decommissioning, migrating historical data to low cost big data and implementing high value use cases to production, they significantly offset their initial capital investments and improved value realization by over 35% after a 3 year journey.
To ensure success, companies that adopt this approach must also invest in robust capabilities such as:
· Transformation planning and business case generation and tracking capabilities
· Strong senior leadership and business stakeholder sponsorship of the transformation program
· Program delivery and interdependency management capabilities
· Change management and adoption investment as part of the transformation initiative
Conclusion
Over the past five years, new data innovations and paradigms have accelerated the data transformation journey. Data lakes now cost less than half of what they used to; curated data sets, scalable cloud solutions and exploration environments have emerged. Companies are gaining confidence in exploiting these tools and are increasingly adopting aggressive techniques to unlock value. As data journeys continue to evolve, leaders will differentiate themselves by balancing their investment in new technology to deliver high value business use cases with the need to continuously optimize their legacy investment.
About the authors:
Brandon Joffs is a managing director at Accenture Applied Intelligence.
Dr. Amy Gershkoff is a data consultant; she was previously Chief Data Officer for companies including WPP, Data Alliance, Zynga, and Ancestry.com.
Ramesh Nair is a managing director at Accenture Applied Intelligence.
RELATED NEWS AND ANALYSIS
-
Ethics and Artificial Intelligence: Driving Greater Equality
FEATURE | By James Maguire,
December 16, 2020 -
AI vs. Machine Learning vs. Deep Learning
FEATURE | By Cynthia Harvey,
December 11, 2020 -
Huawei’s AI Update: Things Are Moving Faster Than We Think
FEATURE | By Rob Enderle,
December 04, 2020 -
Keeping Machine Learning Algorithms Honest in the ‘Ethics-First’ Era
ARTIFICIAL INTELLIGENCE | By Guest Author,
November 18, 2020 -
Key Trends in Chatbots and RPA
FEATURE | By Guest Author,
November 10, 2020 -
FEATURE | By Samuel Greengard,
November 05, 2020 -
ARTIFICIAL INTELLIGENCE | By Guest Author,
November 02, 2020 -
How Intel’s Work With Autonomous Cars Could Redefine General Purpose AI
ARTIFICIAL INTELLIGENCE | By Rob Enderle,
October 29, 2020 -
Dell Technologies World: Weaving Together Human And Machine Interaction For AI And Robotics
ARTIFICIAL INTELLIGENCE | By Rob Enderle,
October 23, 2020 -
The Super Moderator, or How IBM Project Debater Could Save Social Media
FEATURE | By Rob Enderle,
October 16, 2020 -
FEATURE | By Cynthia Harvey,
October 07, 2020 -
ARTIFICIAL INTELLIGENCE | By Guest Author,
October 05, 2020 -
CIOs Discuss the Promise of AI and Data Science
FEATURE | By Guest Author,
September 25, 2020 -
Microsoft Is Building An AI Product That Could Predict The Future
FEATURE | By Rob Enderle,
September 25, 2020 -
Top 10 Machine Learning Companies 2021
FEATURE | By Cynthia Harvey,
September 22, 2020 -
NVIDIA and ARM: Massively Changing The AI Landscape
ARTIFICIAL INTELLIGENCE | By Rob Enderle,
September 18, 2020 -
Continuous Intelligence: Expert Discussion [Video and Podcast]
ARTIFICIAL INTELLIGENCE | By James Maguire,
September 14, 2020 -
Artificial Intelligence: Governance and Ethics [Video]
ARTIFICIAL INTELLIGENCE | By James Maguire,
September 13, 2020 -
IBM Watson At The US Open: Showcasing The Power Of A Mature Enterprise-Class AI
FEATURE | By Rob Enderle,
September 11, 2020 -
Artificial Intelligence: Perception vs. Reality
FEATURE | By James Maguire,
September 09, 2020
BIG DATA ARTICLES