

Data pipeline architecture refers to the systematic and structured approach of designing, implementing, and managing the flow of data from diverse sources to one or more destinations in a reliable, efficient manner. Well-designed data pipeline architecture processes transform raw data into valuable insights to support analytics, reporting, and other data-driven applications and use cases.
Effective data pipeline architecture lets organizations capture the full potential of their data and accommodate increasingly large and complex data volumes with ease. To succeed, you need a thorough understanding of the intricacies of data pipeline architecture, including its components, benefits, challenges, popular tools, and best practices—here’s a detailed look at what goes into this complicated process.
- Data Pipeline Stages
- Data Operations and Infrastructure
- Benefits of an Optimal Data Pipeline Architecture
- Challenges in Data Pipeline Architecture
- Best Practices in Data Pipeline Architecture
- 5 Popular Tools for Data Pipeline Architecture
- Bottom Line: Architecting Data Pipelines for Optimal Data Flow and Resilience
Data Pipeline Stages
A robust data pipeline architecture is made up of several interconnected stages, each playing a unique role in the data processing journey. Understanding the dynamics of these stages and their interactions is essential for designing an effective and efficient data pipeline.
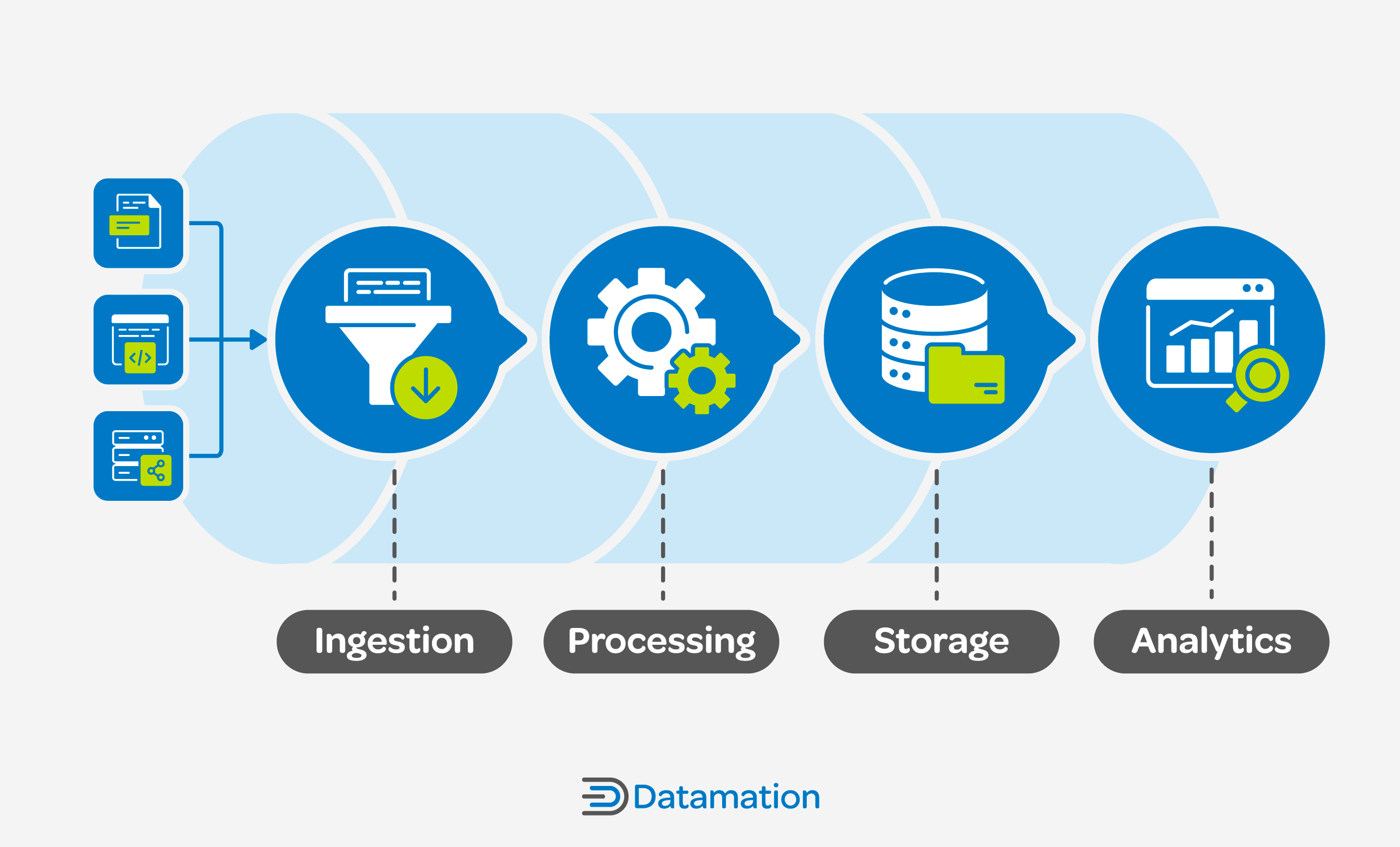
Stage 1: Ingestion
Data source ingestion is the starting point of any data pipeline. In this initial stage, raw data is captured or collected and brought into the pipeline from various sources. Sources might include databases, external application programming interfaces (APIs), log files, or external data streams and streaming platforms, to name a few. Data ingestion can occur in batch mode, where data is collected in predefined intervals, or in real-time (streaming) for immediate processing.
During the ingestion stage, data engineers must address challenges related to data variety, volume, and velocity—known as the “three Vs”—and implement mechanisms to validate and cleanse incoming data for quality throughout the pipeline. A well-executed ingestion stage sets the foundation for downstream processing, storage, and analytics, ultimately allowing for the gleaning of valuable insights.
Stage 2: Processing
Once ingested, raw data undergoes transformation, the process of converting data into a format suitable for analysis or consumption, refining it to ensure accuracy, and structuring it in a way that aligns with the organization’s analytical goals. Transformations may include data normalization/denormalization, the creation of derived features, as well as rudimentary cleaning and enrichment to prepare it for analysis and further downstream tasks.
During processing, data engineers may filter out irrelevant information, aggregate data, and perform complex computations.This stage’s efforts commonly leverage distributed computing frameworks like Apache Spark or specialized processing engines to efficiently handle large-scale data.
Efficient processing is essential for generating meaningful insights. The success of subsequent stages relies on the accuracy and completeness achieved during processing.
Stage 3: Storage
In the storage stage, the processed and transformed data finds a home in repositories such as databases, data lakes, or data warehouses for future retrieval and analysis. The choice of storage solution depends on factors such as the nature of the data, cost constraints (if any), retrieval speed requirements, and scalability considerations. Data engineers must strike a balance between accessibility and cost-effectiveness, opting for storage systems that align with the organization’s data retrieval needs.
The storage stage is essential for maintaining a historical record of the processed data, ensuring its availability for analytics, reporting, and other downstream applications. The storage stage acts as a reservoir of insights, facilitating efficient data management and retrieval throughout the lifecycle of the data pipeline.
Stage 4: Analytics
Processed and stored data is transformed into actionable insights using analytics tools and visualization platforms that reveal valuable information, patterns, and trends in the refined data. Data scientists and analysts leverage various querying techniques, statistical methods, and machine learning (ML) algorithms to extract meaningful patterns and correlations and present them using interactive charts, dashboards, reports, or other visualizations that empower stakeholders to make informed decisions.
The analytics stage involves both extracting insights as well as continuously refining and iterating on analytical processes to enhance the accuracy and relevance of the derived information. Ultimately, the analytics stage is the terminus of the data pipeline, where raw data is transformed into valuable knowledge for driving strategic decision-making within the organization.
Data Operations and Infrastructure
An organization’s data initiatives (and underlying support infrastructure) are usually a joint effort and responsibility of data architects, data scientists, and IT and/or DevOps. In larger organizations, formal data operations (DataOps) teams consisting of cross-functional members take an Agile approach to designing, implementing, and maintaining a distributed data architecture. In either case, data professionals or DataOps teams typically implement DevOps tools as well as specialized solutions for data pipeline orchestration and monitoring.
Supporting Different Organizational Data Needs
Some organizations only require one data pipeline to support a specific critical enterprise task; however, it’s not uncommon for organizations to implement thousands of pipelines, each with its own data movements supporting a different data initiative, from ingestion to analytics.
For example, an organization may have a data pipeline architecture for capturing user registration data via a web form, performing data cleaning to remove invalid or missing values, storing the data in a relational database, and using a visualization platform to build charts and reports against the user registration data in storage. The same organization may also have another data pipeline architecture dedicated to its ML operations, and yet another for ingesting, processing, and analyzing streaming security data of its employees’ real-time network activity.
Data Pipeline Orchestration and Monitoring
Crucially, each data pipeline in an organization requires its own data pipeline orchestration and monitoring mechanisms. Data pipeline orchestration and monitoring is a logical overlay of the four data pipeline stages, providing the necessary end-to-end quality and integrity checks.
As it flows from ingestion and processing to storage and analytics, data must be properly coordinated across the four stages to ensure data quality and resilience; to this end, data orchestration ensures that tasks are executed in the correct sequence, maintaining the integrity and efficiency of the pipeline. Apache Airflow, Jenkins, and Prefect are a few of the popular tools used for data pipeline orchestration.
Continuous monitoring of the data pipeline’s health and performance is essential for ensuring that errors are detected and remediated as early as possible in the data’s journey. Logging mechanisms help track errors, bottlenecks, and any deviations from expected behavior. In most cases, data pipeline orchestration tools include at least basic monitoring tools for data movement visibility and situational awareness.
Benefits of an Optimal Data Pipeline Architecture
A properly architected data pipeline facilitates efficient decision-making and more effective strategic initiatives, allowing data-driven organizations to deliver accurate and relevant data across the four data pipeline stages in a timely manner.
Data Quality and Consistency
By automating data movement and transformation processes, an optimal data pipeline architecture reduces the risk of errors and inconsistencies, ensuring the integrity of the data throughout its journey. With the automation of time-consuming tasks and reduction of manual intervention. The resulting data consistency and reliability minimizes the risk of errors while increasing the reliability of the derived insights and accelerating the overall data processing cycle.
Scalability and Resource Optimization
As data volumes grow, a well-designed architecture can scale horizontally or vertically to accommodate increased data loads without compromising performance or incurring exorbitant cost. The resulting dynamic data workflows and automated processes allow firms to realize substantial cost savings—and with data workflow resources optimized through automation, firms can more efficiently utilize data resources, reduce unnecessary overhead, and maximize their return on investment.
Improved Decision-Making and Agility
Well-architected data pipelines not only allow organizations to respond swiftly to changing conditions and make data-driven decisions on the fly—they also foster collaboration by providing a standardized framework for data handling, making it easier for cross-functional teams to work on data-related tasks. And with timely access to accurate and relevant data, organizations can make better-informed decisions and enhance their strategic planning and execution efforts.
Challenges in Data Pipeline Architecture
When designing a data pipeline, firms must address a number of challenges to maintain the effectiveness of the architecture, to include the following:
- Ensuring Data Quality—Maintaining data quality throughout the pipeline is essential, as poor-quality data can lead to inaccurate insights and fault predictions.
- Reducing Integration Complexity—Integrating disparate data sources and technologies is a complex affair that requires extensive planning and analysis to avoid compatibility issues and other data integration conflicts.
- Maintaining Data Security and Privacy—The protection of sensitive data throughout the data pipeline, from ingestion to analytics, is typically a compliance/legal imperative that requires careful analysis and execution on an ongoing basis.
- Extending Maintainability—Data pipelines may become difficult to maintain over time, especially if they lack proper documentation and version control. Regular updates and active monitoring—supported by both tools and people—are essential for long-term data pipeline viability and maintainability.
- Addressing Scalability Constraints—As data volumes grow, a poorly architected data pipeline quickly becomes unsustainable and difficult to manage. Ensuring proper data quality and delivery over time requires careful consideration of the underlying data infrastructure vis-a-vis current and anticipated future data volumes.
Best Practices in Data Pipeline Architecture
A number of industry-standard best practices allow firms to achieve efficiency, reliability, and maintainability in their data pipeline architecture. Here are the most essential:
- Define Clear Data Objectives—Clearly define the objectives of the data pipeline and be sure to align them with the organization’s overall goals and business strategy.
- Implement Data Quality Checks—Incorporate data quality checks at various stages of the pipeline to identify and rectify issues early in your data’s journey.
- Prioritize Security and Privacy—Implement robust security measures to safeguard sensitive data—these include data encryption, strong access controls, and data governance tools for complying with data protection laws and regulations.
- Document and Monitor—Maintain comprehensive documentation for your data pipeline architecture and establish monitoring mechanisms for quickly detecting and addressing issues.
- Test Rigorously—Conduct thorough testing—including unit testing, integration testing, and end-to-end testing—to validate the reliability and performance of your data pipeline architecture on an ongoing basis.
- Promote Collaboration—Foster collaboration between data engineers, data scientists, and other stakeholders, ensuring that the data pipeline architecture meets the diverse needs of your organization.
5 Popular Tools for Data Pipeline Architecture
A wide range of technologies can be employed in the different stages of a fully-realized data pipeline architecture, including data analytics tools, storage solutions, and data processing and transformation tools. The following are some of the leading tools for data pipeline architecture purposes.
Apache Kafka
Apache Kafka is a distributed streaming platform that excels in handling real-time data feeds. The open source solution is used by over 80 percent of all Fortune 100 companies for building scalable and fault-tolerant data pipelines.
Apache Airflow
Apache Airflow is an open-source platform for orchestrating complex workflows, allowing for the streamlined scheduling and monitoring of data pipeline tasks. Originally developed internally at AirBnB, Airflow is now the leading solution for orchestrating data flows across the pipeline and building seamless data access and integration processes.
Apache Spark
Apache Spark is a general-purpose data processing framework and cluster computing system capable of performing processing tasks on expansive data sets with ease. For this reason, the open source solution is currently the dominant data platform for big data processing and analytics, often used in the processing stage of data pipelines.
AWS Glue
AWS Glue is a fully managed extract, transform, and load (ETL) service that simplifies the process of preparing and loading data for analysis. Based on Apache Spark’s Structured Streaming engine, Glue enables organizations to build real-time, fault-tolerant data pipelines for supporting end-to-end data streaming pipelines.
Microsoft Azure Data Factory
Microsoft’s Azure Data Factory is a cloud-based data integration service that enables the creation, scheduling, and management of data pipelines. For organizations hosting their data infrastructures in Azure clouds, Data Factory is the ideal for ingesting/integrating data across different platforms—Azure SQL Database, Azure Blob Storage, and Azure Data Lake Storage, and more.
Databricks
Databricks is a unified analytics platform that combines data engineering, ML, and analytics through a single interface, making it suitable for end-to-end data pipeline solutions. Like AWS Glue, Databricks is primarily powered by the open source Apache Spark platform for its compute clusters and SQL warehouses. The platform is available both as a standalone offering from Databricks, as well as within Microsoft Azure’s cloud ecosystem (i.e., Azure Databricks).
Bottom Line: Architecting Data Pipelines for Optimal Data Flow and Resilience
A well-designed, fully-realized data pipeline architecture provides organizations with a robust, future-proof framework for handling diverse data sources and deriving valuable insights. By understanding the previously mentioned data pipeline intricacies and drawing from best practices, organizations can harness the full potential of their data to remain formidable in today’s competitive operating environments.