Datamation content and product recommendations are
editorially independent. We may make money when you click on links
to our partners.
Learn More
Earlier this year, Google CEO Sundar Pichai announced that Google was moving from mobile-first to AI-first. If the company is as successful shifting away from mobile as they were shifting towards mobile, the change could alter more than just Google. It will likely force other companies to change the way they operate in order to keep up. In much the same way that mobile-first required a new approach to strategy, design and development, AI-first will require a new perspective to properly benefit from its impact.
Many companies will say they’re “AI-first,” but how many will truly be able to transform?
Here are my three rules for being an AI-first company, regardless of your industry.
Rule #1: Think in Singles, Not Home Runs
Machine learning (ML) is about hitting singles and doubles, not home runs. Focus on building a muscle that builds many smaller features.
Forget what you’ve heard about artificial intelligence (AI) or ML being magic pixie dust that will automate away 50 percent of our jobs. While there have been many great anecdotes about the power of AI, those are mostly superficial.
The first instinct of business people is to look for the perfect home run use for ML: either automating a process for massive efficiency gain or a breakthrough in customer experience (to sell more of course). In reality, teams that effectively deploy ML build out competence over a long time by hitting a series of singles and doubles, not out-of-the-park home runs.
The perfect example of this is Gmail.
On the surface, the spam filter is Gmail’s killer ML app. Algorithms scan billions of emails every day and remove the headache of a noisy inbox. But dig a little deeper and you’ll find many other small and big features in Gmail which are ML-powered:
- CCs to add — suggests to user additional people to add to emails
- Check for Attachment — stops user from sending email without an attachment if text suggests there should be an attachment
- Flag Emails as Important — places a small flag on incoming emails to help user prioritize
- Translate Text — translates automatically between two languages
The Gmail developers have removed friction and improved the user experience of the product inch-by-inch with small, ML-enabled injection.
Rule #2: Choose the Right Hammer
Simply knowing which nails require which hammer could be the difference between success and failure.
If ML projects had a batting average I’d doubt it would break .100. Even when compared to software broadly, which is known for high failure rates, ML fails a shocking amount of the time.
Usually this is because product teams don’t fully understand the problem they’re trying to solve. I’ve seen a large legal research company invest over $20 million into a project which could have been solved by a handful of developers over a month. Conversely, I’ve seen many large banks under-invest in ML, building to alpha products, but running out of money before they could be put into production.
I like to break ML projects into four categories:
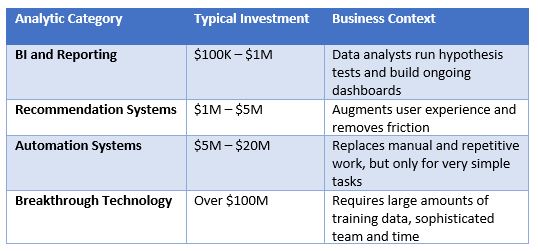
ML projects often fail because people confuse recommendation systems for automation systems and vice versa.
Let’s go back to our Gmail example. The feature that flags email as spam and the feature that flags email as important looks similar. In both cases it’s a binary yes/no that the algorithm predicts. The difference is that they have an entirely different user experience and set of requirements.
Spam filters are doing something very simple; I can say immediately whether an email is spam or not. It needs to be highly accurate (because how often do you check your spam folder), but not let too many emails through. It’s a perfect case of automation.
On the other hand, flagging an email as important is quite complicated. It can depend on the person, the contents, the time of day and any number of other factors. Gmail would never dream of filtering out ‘unimportant’ emails or even rearranging your inbox, because it’s not accurate enough. They’re trying to augment the user experience and build recommendations.
Andrew Ng has a great quote about this: “Anything that a human can figure out in two seconds can probably be automated by machine learning.” I call this the “two-second rule,” and it illustrates that you need to think hard about whether machines are up to a complex task. Don’t expect magic from automated systems — in most cases the magic pixie dust has significant human lifting behind it.
Often I’ll ask executives whether they’re trying to channel Steve Jobs or Andy Grove. Jobs starts with the user experience and builds backward to a technology solution (which can involve ML). Grove brings Hungarian-style discipline to a workflow: Break it down into simple enough pieces that you can automate and build quality around.
Rule #3: Data Beats Algorithms
Don’t try ML before figuring out your data, especially in the enterprise.
It’s easy to put the cart before the horse in ML. Most organizations jump to implementing algorithms or building analytics before they are on solid footing with data. It’s like the old adage: “Garbage in, garbage out.”
This is especially true for large enterprises. Executives map out neat definitions of where data lies and the organizations which own them. The reality is that data in the enterprise today is a spaghetti mess. There are hundreds of systems, applications and databases which contain a myriad of inconsistent and siloed data. It’s made worse by years of M&A, reorgs and changing business.
In fact, the enterprise mess of data is so bad that even basic analytics, like counting the number of customers within a segment or the amount of spend in a category, is difficult and time-consuming. It’s no surprise then that when analysts try to apply more sophisticated algorithms, those algorithms are not very effective because of their data.
The boring, unsexy task of collecting data is much harder to copy than fancy algorithms. Not only is data more important, but it’s also an enduring competitive moat for an organization.
Many companies will swan dive into AI-first and struggle to figure out why their investments aren’t paying off. Many will find that AI enhances their user experience and bottom line. The difference will be how genuine their efforts are to truly understand how AI works and what it can (and cannot) do for them.
To summarize:
- Don’t try to hit home runs. Focus on singles and doubles across an application.
- Understand the problem before picking technology. Match your hammer to the nail if you want successful projects.
- Address your data mess before looking to fancy algorithms.
Eliot Knudsen is the data science lead at Tamr, where he works with Fortune 100 clients to reduce spend by unifying sourcing data and implementing procurement analytics. Eliot is a graduate of Carnegie Mellon University, where he studied computational mathematics, statistics and machine learning.
Photo courtesy of Shutterstock.
-
Huawei’s AI Update: Things Are Moving Faster Than We Think
FEATURE | By Rob Enderle,
December 04, 2020
-
Keeping Machine Learning Algorithms Honest in the ‘Ethics-First’ Era
ARTIFICIAL INTELLIGENCE | By Guest Author,
November 18, 2020
-
Key Trends in Chatbots and RPA
FEATURE | By Guest Author,
November 10, 2020
-
Top 10 AIOps Companies
FEATURE | By Samuel Greengard,
November 05, 2020
-
What is Text Analysis?
ARTIFICIAL INTELLIGENCE | By Guest Author,
November 02, 2020
-
How Intel’s Work With Autonomous Cars Could Redefine General Purpose AI
ARTIFICIAL INTELLIGENCE | By Rob Enderle,
October 29, 2020
-
Dell Technologies World: Weaving Together Human And Machine Interaction For AI And Robotics
ARTIFICIAL INTELLIGENCE | By Rob Enderle,
October 23, 2020
-
The Super Moderator, or How IBM Project Debater Could Save Social Media
FEATURE | By Rob Enderle,
October 16, 2020
-
Top 10 Chatbot Platforms
FEATURE | By Cynthia Harvey,
October 07, 2020
-
Finding a Career Path in AI
ARTIFICIAL INTELLIGENCE | By Guest Author,
October 05, 2020
-
CIOs Discuss the Promise of AI and Data Science
FEATURE | By Guest Author,
September 25, 2020
-
Microsoft Is Building An AI Product That Could Predict The Future
FEATURE | By Rob Enderle,
September 25, 2020
-
Top 10 Machine Learning Companies 2020
FEATURE | By Cynthia Harvey,
September 22, 2020
-
NVIDIA and ARM: Massively Changing The AI Landscape
ARTIFICIAL INTELLIGENCE | By Rob Enderle,
September 18, 2020
-
Continuous Intelligence: Expert Discussion [Video and Podcast]
ARTIFICIAL INTELLIGENCE | By James Maguire,
September 14, 2020
-
Artificial Intelligence: Governance and Ethics [Video]
ARTIFICIAL INTELLIGENCE | By James Maguire,
September 13, 2020
-
IBM Watson At The US Open: Showcasing The Power Of A Mature Enterprise-Class AI
FEATURE | By Rob Enderle,
September 11, 2020
-
Artificial Intelligence: Perception vs. Reality
FEATURE | By James Maguire,
September 09, 2020
-
Anticipating The Coming Wave Of AI Enhanced PCs
FEATURE | By Rob Enderle,
September 05, 2020
-
The Critical Nature Of IBM’s NLP (Natural Language Processing) Effort
ARTIFICIAL INTELLIGENCE | By Rob Enderle,
August 14, 2020
SEE ALL
BIG DATA ARTICLES