Datamation content and product recommendations are editorially independent. We may make money when you click on links to our partners.
Learn More Data lakes and data warehouses are two ways of storing data in large quantities with very different approaches, each with its own strengths and weaknesses.
Rather than being mutually exclusive, they’re complementary solutions that can work effectively to provide business intelligence for organizations that implement them wisely. This article compares both storage solutions on their features and use cases to help you better understand the difference.
What Is a Data Lake?
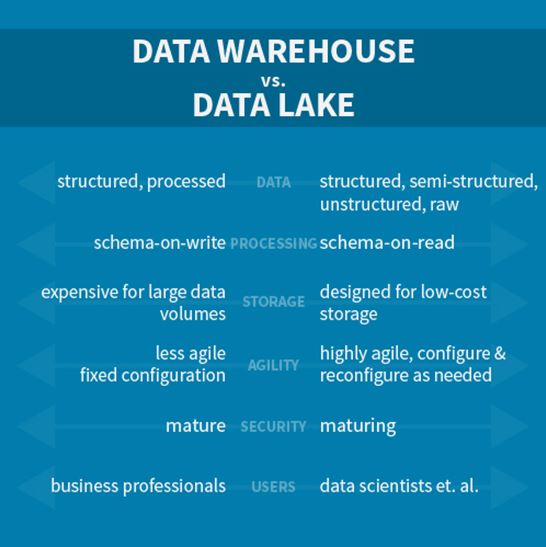
A data lake is a storage repository that holds a vast amount of raw data in its native format until it is needed. Data lakes use a flat architecture to store data so it is completely unstructured, retaining it in the format in which it was originally ingested.
Each data element in the lake is assigned a unique identifier and a set of extended metadata tags. When queries are run, they can run against the limited, smaller data set with the specific tags rather than having to process all the data stored in the lake.
Data lakes are well-suited to storing unstructured data from disparate sources and in different formats—for example, social media posts, multimedia files, log files, emails, and data from Internet of Things (IoT) devices. These are cost-effective storage solutions for businesses who need to rapidly capture and retain huge amounts of data without needing much transformation.
More complicated than data warehouses, data lakes typically need to be set up by data scientists or engineers with the expertise to interpret and organize raw data before it can be processed. They’re also more flexible than data warehouses—users can more easily add and store more data and configure data models and applications—but they’re also less secure and require more expertise to use.
Because data stored in lakes tends to be disorganized, over time it can stagnate and lead to “data swamps.”
What Is a Data Warehouse?
A data warehouse is a hierarchical repository of structured data integrated from multiple sources and organized for analysis—for example, customer relationship management (CRM) data and financial records. They often use multiple databases for different types of data storage—ingestion, staging, and transformation, for example—and for processing.
The structured database environment makes them better suited for analytics, business intelligence (BI), and online transaction processing than data lakes, and can be used in conjunction with them to provide the data processing capabilities lacking in data lakes.
Business or data analysts with some awareness of the functions and outcomes of a specific processed data set can typically set up a data warehouse, while data lakes are far more complicated and require more specialized knowledge. Less flexible than data lakes, data warehouses have a more rigid structure that is difficult to change once it is built. They’re more expensive, but they’re also more secure.
Bottom Line: Data Lake vs Data Warehouse
While both data lakes and data warehouses are repositories for storing large amounts of data, their differences make them better suited to different use cases. It comes down to what users want out of the data.
If they know what they are looking for—monthly sales reports or in-store vs. website traffic, for example—then a data warehouse is a better choice. Organizations that want more flexibility to search for more amorphous information—what time of day is web traffic busiest, or how do weather patterns impact sales—then a data lake is a better fit.
Healthcare organizations, educational institutions, and businesses in the transportation industry could benefit from the flexibility to store both structured and unstructured data—all three industries generate massive amounts of raw data used for a wide range of purposes.
But if the goal is strictly business analysis, a data warehouse is a better choice. Data warehouses designed to process structured data and provide insights and reports that can give organizations a better understanding of their customer base, pricing models, historical sales data, market trends over time, and more.
Enterprises in the financial or business sectors that use vast volumes of structured data can make it available across the organization rather than limiting it to use by a handful of data scientists, making it much more useful for their needs.
For many enterprises, the choice should not be “data lake or data warehouse,” because the two are complementary. The best approach for some cases is to implement both and use them in tandem. Organizations that are already using a data warehouse might implement a data lake to store new data sources, for example, providing a repository for archival data moved out of the warehouse.